
Bloom Filters
This post deep dives into what is bloom filters and what are their applications in real-world systems


Problem Statement
Let’s say we have to support the following two operations using any data structure:
Insert(movie): should store the movie name(string) in the data structure
query(movie): returns boolean, should tell if movie exists in the data structure or not
Now, I know what you’re thinking that we can support such an operation using Java HashSet kind of data structure that supports insertion and lookup in O(1) time complexity.
But, the main problem here is that the hashtable consumes a large amount of memory. Assuming the average size of the movie name as `m` and the number of movies to be inserted as `n`. The total memory required would be O(n*m).
Is there a better way to handle this?
Enters the solution: “Bloom Filters”
What are Bloom filters?
Bloom filters are a space-efficient probabilistic data structure that helps in solving the problem: “Does the element exist in the set (data structure) or not?”
When we perform the query(element) operation in the Bloom filters data structure, it can answer the question in either of the two responses:
“Firm No”: This answer by the Bloom filters data structure represents that the element for sure does not exist in the data structure.
“Probably Yes”: This answer by the Bloom filters data structure represents that the element might or might not exist in the data structure. Probably yes can also be termed as “false positives are possible” meaning even though the element does not exist for real in the Bloom filters, the response will be yes. That’s why, it’s called probabilistic in nature.
Tradeoff: Space vs Accuracy
The biggest advantage of using a Bloom filters like kind of data structure is that it consumes a lot less memory compared to your Java Hashset but also provides the possibility of false positives.
This is a typical system design tradeoff, you get some(less space), you lose some(accuracy)!
Let’s go ahead and now understand the internals of the Bloom filters in depth.
Internals of Bloom filters
Let’s consider we have to support the above-discussed operations:
Insert(movie): should store the movie name(string) in the data structure
query(movie): returns boolean, should tell if movie exists in the data structure or not
Let’s take an example. Imagine we have an array of 10 buckets where each bucket consists of a single bit that is set to zero. Since it’s a bit, it can only have two values: either 0 or 1. Initially, all 10 bits are set to 0.

For insert(movie) operation, we have to perform the following steps:
Hash the movie name
Take the hash value % 10
Set the corresponding bit (hash value % 10) to 1 in the array
Repeat the Step 1 to Step 3 using three different hash functions.
Consider we have three hashing functions as H1(x), H2(x), and H3(x), and we hash incoming movie names with all three hashing functions to produce the following values.
H1(“Harry Potter”) = 2
H2(“Harry Potter”) = 3
H3(“Harry Potter”) = 6
H1(“Mission Impossible“) = 1
H2(“Mission Impossible“) = 4
H3(“Mission Impossible“) = 6

For query(movie) operation, we have to perform the following steps:
Hash the movie name
Take the hash value % 10
Find the corresponding bit in the array using all three hashing functions used at the time of hashing. Let’s call them HashValue1, HashValue2, HashValue3
If either of the bits i.e. HashValue1, HashValue2, or HashValue3 is set to 0, that means the movie does not exist in the data structure and the answer becomes “Firm No“. Otherwise, if all of the bits are set to 1, then the answer becomes “Probably Yes“
Case of “Firm No“:
Imagine, for query(“Lord of the Rings“), these are the hash values produced:
H1(“Lord of the Rings”) = 3
H2(“Lord of the Rings”) = 5
H3(“Lord of the Rings”) = 8
Although the 3rd bit is set, the 5th and 8th bits are not set, and thus we can confirm that the movie “Lord of the Rings” does not exist in the data structure.
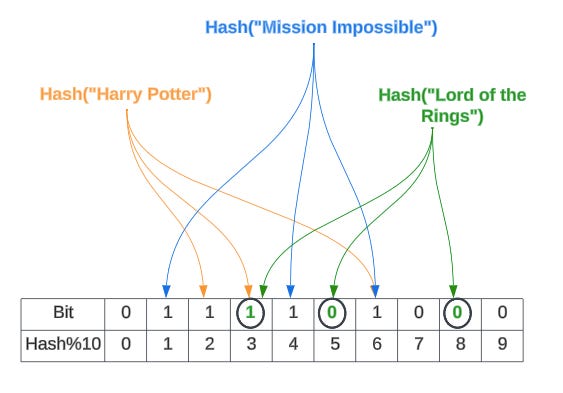
Case of “Probably Yes“:
In a similar fashion, for query(“Fast and Furious“), these are the hash values produced:
H1(“Fast and Furious”) = 2
H2(“Fast and Furious”) = 4
H3(“Fast and Furious”) = 6
Although all the bits are set, we never really inserted the movie “Fast and Furious“ in our dataset. This happened purely because of the collisions that set bits of the new movie coincided with the set bits of the previously inserted movies. And that’s why the data structure response will be “Probably Yes“.

Key Takeaways
As we understood through the example, the hashing functions played a critical role in the functioning of bloom filters. So, we must choose good hashing functions that are fast and produce even and randomly distributed values among the hash size as much as possible. Always remember, that the Bloom filters are as fast and reliable as the hashing functions used for hashing the keys.
Also, we just considered an example of a Bloom filter having only 10 bits but in real-world use cases, we might use multiple Bloom filters and different hashing functions for each Bloom filter instance to avoid collisions as much as possible.
Something you should note here is that bloom filters provide constant time complexity and constant space complexity for both insert(element) and query(element) operations assuming the number of hashing functions used for hashing the keys is constant.
Bloom filters are initially created keeping in mind the size of the entries that bloom filters must store at any given point of time. However, if you want to support more entries, Bloom filters are infinitely scalable. If you realize that the Bloom filter you started with has hashed too many keys and is having too many collisions, you can always create a new Bloom filter and insert the new elements without disturbing the original Bloom filter. For query(element) operation, you might have to check in all instances of Bloom Filters and then take a decision accordingly.
Use Cases
Bloom filters are used in today’s world for multiple number of use cases. The underlying core strategy of using the Bloom filter remains the same we want to avoid an expensive lookup and first use a space and time-efficient lookup. Here are some of the examples.
Many databases (including SQL and NoSQL) use Bloom filters for various purposes. One common use case is to avoid disk reads. If I have a large on-disk database and I want to know if an element `foo` exists in it or not, then I can potentially query the Bloom filter first. If it exists in Bloom Filter, that means it potentially exists(chance of false positive) and we can continue the database lookup. If it doesn’t exist in the Bloom filter, we can avoid the database lookup and return the empty response.
Another interesting usecase of bloom filters is to build indexes in Postgre. You can build bloom indexes and that helps in determining whether a row (determined uniquely by primary ID) exists in the database or not.
Akamai uses Bloom filters to prevent “one-hit wonders”. Only caches the page when the page is requested for the second time. This is because Akamai found out that most of the pages requested on web are only requested for once. If the user is requesting for the second time, then it should be cached.
Bloom filters are used to prevent storing weak passwords. In case of false positives, users might be asked for another password, but it avoids the probability of storing a weak password.
If a username already has been taken on a social platform(like Instagram) or not, bloom filters will do a much better job than running a query on millions of records in the database.
Not showing same movies as recommendations(for netflix) or avoid showing same ads to the user on any ads platform are also great examples where bloom filters fit perfectly.
Conclusion
If your use case requires you to not have any false negatives and may be okay to have a few false positives, then Bloom filters are a perfect fit for your use case. You should think about creating a bloom filter big enough that expects a certain number of entries. But if not big enough for supporting future use cases, then don’t worry as you can add more bloom filters on top of it. In future editions, I will share with you on how to implement Bloom Filters using live code. :)
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your LinkedIn network and schedule a free 30-minute 1:1 with me:) Ping me on Linkedin!
Resources
Bloom Filter by Wikipedia
Bloom Filters by Alex Xu
Bloom Filters by Redis
Introduction to Bloom Filter by Baeldung
how do we handle delete operation from bloom filter?
if we unset a bit, it can affect other keys' results
Nice read.