
How to find nearby entities?
Uncover the world with Geohashing, a clever way to encode locations into short codes. Learn how it works.

What’s the problem statement?
I am pretty sure if you open 10 apps of different categories on your phone, you will find at least half of them have a feature that helps you find/suggest nearby entities. The entities could be people, places, etc.
A classic example of this would be the popular app: Google Maps which helps you explore what are the nearby petrol pumps/restaurants/ATMs/Hospitals/malls/parks etc. Similarly, in the case of ride-hailing platforms like Uber/Lyft, it could be to find what are the nearby drivers — it doesn’t get shown intuitively to the end customer but in the backend, it’s doing the same process.
If you translate this feature of finding what are the nearby entities in terms of software engineering, the problem statement is: Given the current location(latitude, longitude) of the user, find the nearby entities.
However, it isn’t mentioned how far should the system look to find nearby entities for the end user. Is it 1km or 10kms or 100kms? Thus, we need to attach some distance metric to the equation and the problem statement becomes:
Given the current location(latitude, longitude) of the user and a certain distance threshold, find the nearby entities.
As an example for this blog’s reference, from here on, I will try to solve: How to find nearby restaurants within a certain distance? But this is easily scalable to understand for other applications.
Brute Force solution
The brute-force way to approach this problem is in two parts:
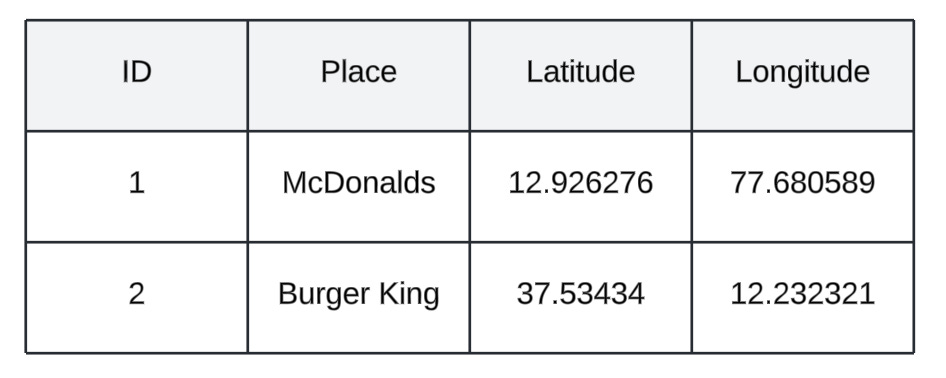
Storing all the newly opened restaurants in an SQL table. This could be either done manually by people who make an entry into the SQL table or it could be automated via a pipeline. The SQL table schema could look like:

Now, for a given user’s location (latitude, longitude) we have to find what are the nearby restaurants within a certain distance threshold (let’s say 1km). To solve this, the backend application can fire a query to the database which can filter out all the places nearby within a certain threshold:
SELECT id, name, latitude, longitude, ({mathematical formula to calculate distance b/tw two pairs of lat/lng}) AS distance FROM places HAVING distance <= :radius ORDER BY distance;
Why this brute force approach is not a good solution?
We are practically scanning through all the places present in the table.
As our system ingestion pipeline adds more places, it could scale to millions of places and thus going through all the records for every search query(user’s lat/lng, distance) is not a scalable solution. The end user would have to wait for a long time while our backend system goes row by row to figure out all places within 1km.
You cannot use indexing as a benefit for your use case to reject a large chunk of data while querying.
How can we do better? Enters the solution: GeoHashing Algorithm
Geohashing Algorithm
Geohashing is a method of encoding geographic locations(latitude and longitude) into short alphanumeric strings. It provides a way to represent any location in a compact and efficient string format, which can be useful for various applications, such as mapping, location-based services, and spatial databases.
For example:
The location (latitude = 37.75780692, longitude = -122.52000013) can be converted to a Geohash string: “9q8ygcxejj67”.
Let’s deep dive into this.
How does GeoHashing work?
The Geohashing algorithm assumes the whole world is made up of a grid of rectangles. Each rectangle can be subdivided into a further smaller number of rectangles.
For example: consider the below image. In this image, we can see the whole world can be considered of some rectangles at Level 0. If we try to zoom in on the rectangle “t“ by clicking on it, there would be sub-rectangles as represented in Level 1. If we try to zoom in on rectangle “d“, there would be more sub-rectangles represented in Level 2. The geohash formed so far would be the concatenation of the characters we clicked on so far: “td“ and this process could continue as much as want to zoom in.
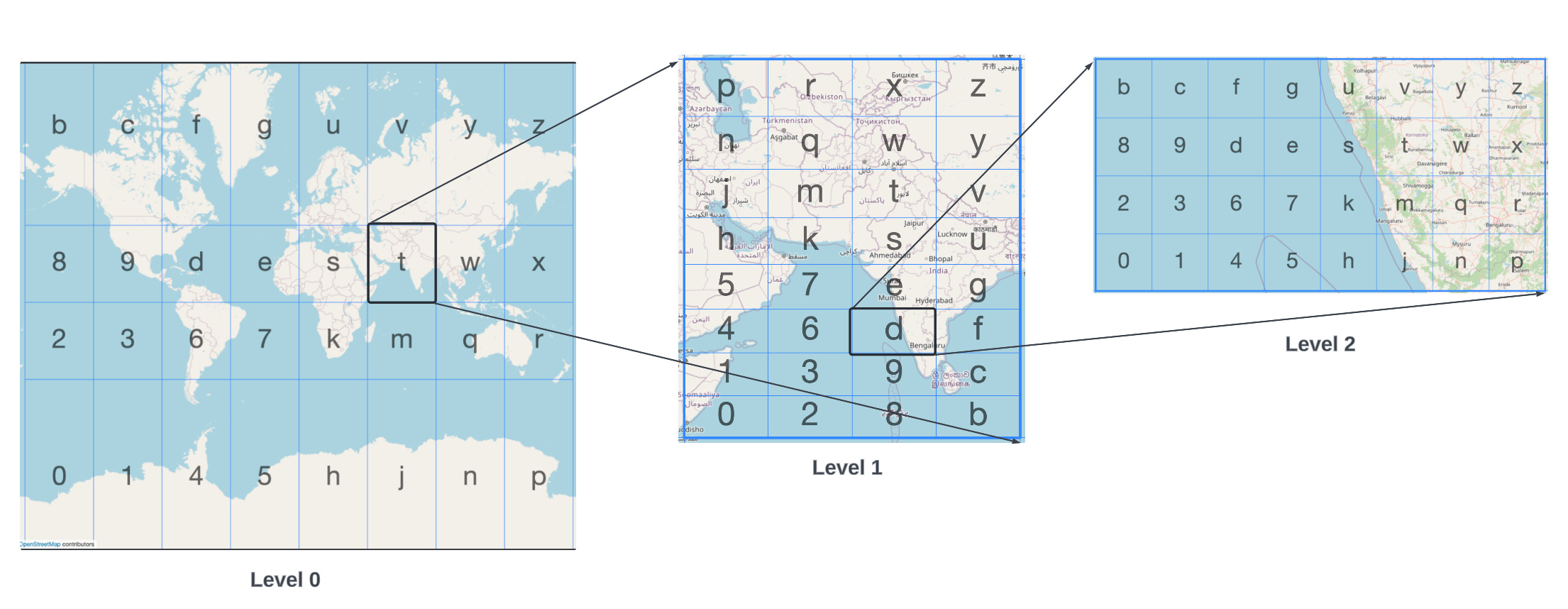
The beauty of this concept is that as we zoom into any rectangle, we are going deep into some geographical area of the whole world. If we continue to do this for approx 10 times, we might reach a rectangle that ideally represents a rectangle of a few meters square area.
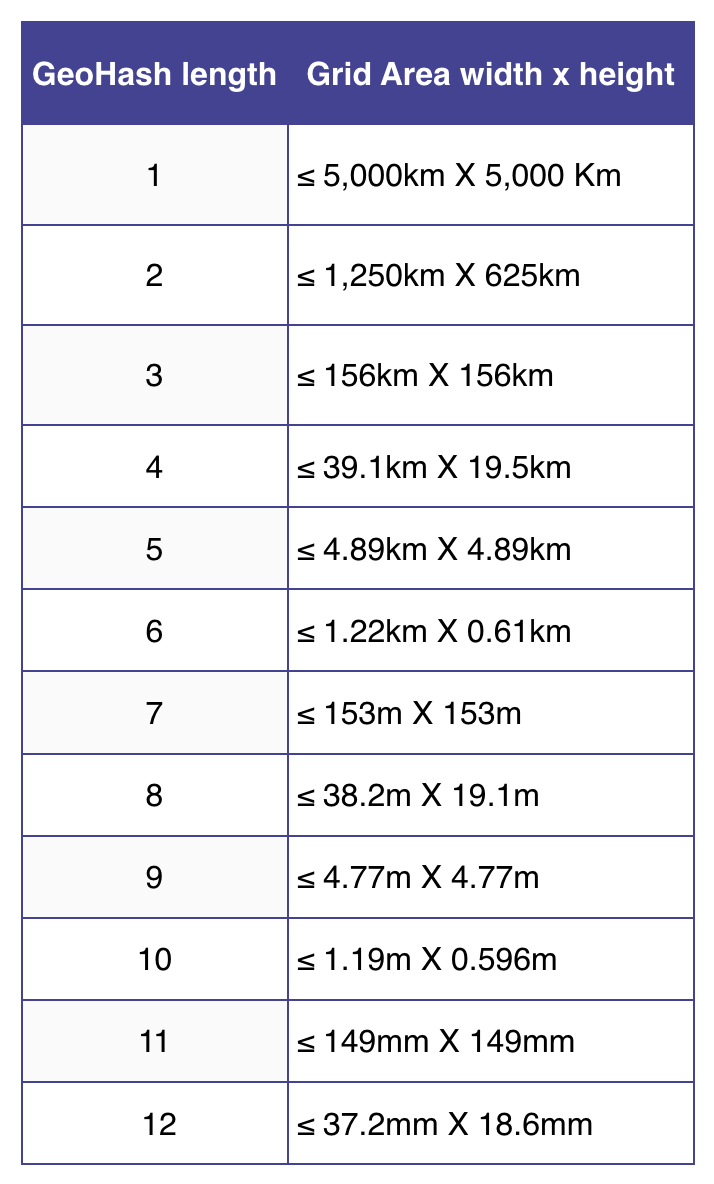
A good observation at this point would be that the longer the length of the Geohash, the more it represents the granularity with which a geographical location is represented.
A longer string provides a more precise location, representing a smaller geographical area. For example, a Geohash with 8 characters can pinpoint a location within a few meters. A shorter string provides a less precise location, representing a larger geographical area. For instance, a Geohash with 5 characters might cover an area of around a few kilometers.
Considering some standard implementations of the Geohashing algorithm, the geohash length can correspond to the following grid area.
I highly recommend you to try out this tool: https://geohash.softeng.co/
How is this helpful?
Well, remember earlier when we were storing all the latitudes and longitudes in the SQL table? Then, we were comparing the distance of the user’s lat/lng with all other places in the table.
Now, Imagine that we have a GeoHash string stored in the “Places” SQL table for every place that represents the Geohash string up to 10 characters in precision.

Now, we can follow the below steps to find all the places within a certain distance of the user’s lat/lng.
Given the user’s latitude/longitude.
Covert the user’s lat/lng to the corresponding GeoHash string (let’s say it’s “sq8tw2gjrhhg“)
As you already know the precision in the Geohash string represents the granularity with which a geographical location is represented. Let’s say we want to find all places within a 5 km square area of the user, we will pick the first 5 characters out of the user’s location GeoHash string.
Then, we will do a string LIKE comparison to filter all the relevant places using the following query:
SELECT id, name, latitude, longitude, geohash FROM places WHERE geohash LIKE {user's location geohash}
As you would have observed, picking the first 5 characters helped us determine how far we want to search for places from the user’s lat/lng.
Few points:
The good thing about the Geohashing algorithm is that it allows you to do string comparisons to filter out the places. The string comparisons are faster than float comparisons.
We still might be doing full table scans to find the relevant places. There has been no indexing done till now. Even if you do indexing on the full 10-length geohash stored in the SQL table, there might be some geohash indexes that have only 1 place inside the index. Hmm, not a very good use case for building indexes.
Let’s understand what other optimizations can we do.
Further Optimizations
Optimization 1: Store only G4, G5, G6 Geohashes
Do we need to store full 10-length geohashes for every place? The answer is no because the full 10-length geohash represents the maximum granularity of the location which could be within a few meters square area. But, when we search for places, we want places within a few kilometers. For example: users might want to search for places within (1kms or 5kms or 10kms square area) etc.
That’s why an optimization at this point would be to only store 4-length GeoHash, 5-length Geohash, and 6-length GeoHash. All other Geohash lengths either represent too far or too close location to the user’s lat/lng.

Few points:
The good thing about storing G4, G5, and G6 length geohashes is that now you can build individual indexes on top of these individual length geohashes.
The next time you are going to run the below query, it will fetch you all the locations within a 5 km square area.
SELECT id, name, latitude, longitude FROM places WHERE geohash5 = {user's location geohash upto 5 characters}
Optimization 2: Serve your reads from the cache
As a last optimization, stop querying your database every time a user searches for places on your application. Just dump the G4, G5, and G6 length geohash indexes data into a cache and serve your reads from the cache. Also, once you add a new place in the system using a database write, it’s okay to warm up your caches with a time delay and provide eventual consistency to the end user.
Edge case: If the user’s lat/lng is close to a line sharing two grids that have no common prefix, then it’s a problem. Geographically, the locations are close, but since they don’t have a common prefix, you would completely miss out on searching locations on one side of the grid.

Thus, to avoid missing nearby locations, it can be useful to extend the search area slightly. How? For any Geohash, there are eight possible neighboring Geohashes: north, south, east, west, northeast, northwest, southeast, and southwest. You can calculate these neighbors by adjusting the latitude and longitude of the target Geohash slightly and then re-encoding them into new Geohashes.
Consider these eight geohashes for filtering locations and this ensures that all potentially relevant points are considered
That’s it, folks for this edition of the newsletter. In future editions, I will cover some more algorithms related to location search like quadtree. Stay tuned:)
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Geohashing Algorithm by Code with Irtiza
Design Proximity service by Code with Irtiza
Quadrant Geohash algorithm
Can you explain the reason behind why plain hashing on the geohash string wont work? As you wrote in this point?
> We still might be doing full table scans to find the relevant places. There has been no indexing done till now. Even if you do indexing on the full 10-length geohash stored in the SQL table, there might be some geohash indexes that have only 1 place inside the index. Hmm, not a very good use case for building indexes.
Wow. This is the most helpful post I ever came across. Thanks a lot.