
System Design Study: Mysql High-Availability by Flipkart
This article deep dives into ALTAIR - a high availability MySQL platform at Flipkart

Brief Background
Flipkart has thousands of microservices. These microservices were initially deployed on on-premise data centers. On-premise data centers are those physical machines owned by the company itself. Then, for some time, Flipkart used public cloud networks for hosting data centers and is now using a hybrid approach (both on-premise and public cloud networks).
These microservices use MySQL for their data storage.
Why MySQL?
Well, the microservices include logistics, supply chain, order management services, etc. The tables for storing data produced by these services are highly relational meaning one-row record in a specific table should know about the other records in other tables so that we can perform JOINS on multiple tables and get the desired data in one query. That’s why MySQL seemed to be an appropriate choice here.
Problem
The problem was something that every company would usually face when they want to grow from 0 → 1 and ship things fast.
Initially, every team at Flipkart used to host their own MySQL clusters. This is a problem because of the following reasons:
developer skillsets might vary across teams on how to get the best performance, scaling, database tuning, etc.
less developer bandwidth would lead to slow feature rollouts covering across teams
Core things like security, auditing, and compliance of the database were different due to the difference in standard procedures followed across teams.
Solution
Flipkart realised that they need to centralize things so that context on how to get the best of everything which is discussed above is built over time within one team or group of teams.
Enters Flipkart homegrown solution — ALTAIR
ALTAIR is Flipkart’s managed MySQL as a service that takes away all the common developer concerns for hosting a database as well as making changes to it in the future. Let’s comprehend it using the below image for what folks at Flipkart have developed:

What is Availability and why it’s important?
Availability is referred to as the probability that your service will be able to respond with a successful response. Now, if you are a Software Engineer, you know that the probability that your service can respond to every request successfully is definitely not 100% because of production bugs, runtime issues, etc.
Instead, what we can try to achieve is called high availability which means defining an SLA(service level agreement) i.e. our service is going to be some percentage available at all times.
If availability is 99.0 percent, it is stated to be “2 nines,” and if it is 99.9 percent, it is called “3 nines,” and so on. Thus, every service in all architectures is trying to achieve high availability by chasing as many “nines” as possible. FYI: It’s a little difficult to chase beyond four “nines” i.e. 99.99% availability.
Flipkart is a big company and has multiple services. Due to multiple MySQL clusters being managed by individual teams, the architecture is prone to being less available as the MySQL clusters wouldn’t be configured in the best configuration.
Flipkart’s decision to design MySQL as a service by proposing the ALTAIR system is an effort towards removing the developer’s database-related concerns and thus chasing the high availability of the overall ecosystem.
Introduction: ALTAIR
ALTAIR works on a trivial yet powerful MySQL configuration: primary-replica aka master-slave
The primary instance is responsible for handling writes and reads from the services.
The replica instances asynchronously replicate the data from the primary instance and serve only read requests.

The primary instance has a critical responsibility i.e. handling write requests. Thus, the master instance must be highly available. However, instance failures in on-premise data centers are common which can lead to lower availability and thus degraded customer experience. Thus, when a master instance is failing or fails, the monitoring system of the recovery workflow should trigger the process of promoting a slave instance to be the new primary.
This is called a failover process and post the failover, clients should be able to find the new primary and redirect the writes to the new primary.
If you connect the dots, the failover process is directly tied to the high availability of the ecosystem. Whenever, due to any reason, the services are facing low availability or might face in the future, we must trigger a failover process. This makes the failover process a critical piece to achieve high availability and thus we need to ensure the failover process CANNOT FAIL at any cost.
Before we deep dive into the failover process steps, let’s deep dive into the ALTAIR architecture.
Architecture of ALTAIR

Key components inside ALTAIR include MySQL instance(primary-replica), Agent, monitor, zookeeper, and orchestrator.
Here’s a brief overview of what’s happening inside ALTAIR:
Alongside every primary/replica instance of MySQL, an agent is running as a daemon in the background that is monitoring the overall health (including MySQL disk usage, replication status, and lag) of the running MySQL instance. The agent sends the health information every 10 seconds to the monitor instances via an Elastic Load balancer(ELB).
Multiple monitor instances are running and each monitor instance is assigned to own the health updates of a few MySQL instances.
Each monitor node receives the current state from the updates sent by the agent. It also asks the Zookeeper to read the old state. If there is a change in state and failover is required, the Monitor instance updates the Zookeeper and notifies the orchestrator for triggering the failover process.
The orchestrator node checks if the failover is required or not after performing some validation checks. If the failure is guaranteed, the orchestrator triggers the failover process.
Now that we have understood how the ALTAIR failover process is designed, let’s deep dive into the actual failover process to understand more.
Steps for an on-premise failover process
Summing up what we discussed as part of ALTAIR’s design, Flipkart describes the failover process in four steps
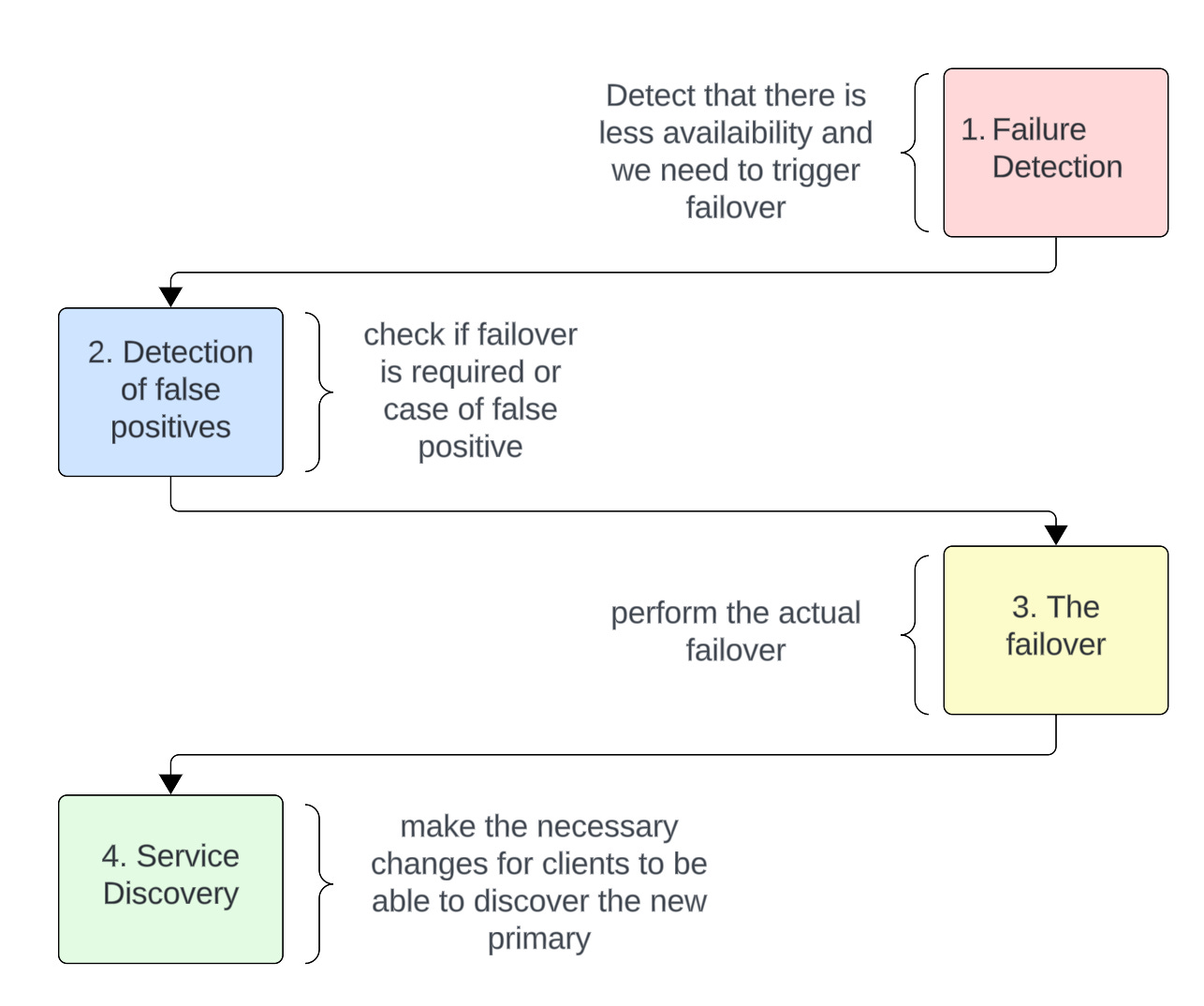
Step 1: Failure Detection
This step consists of determining that the primary instance has started failing because of reasons like power loss, hardware failure, planned maintenance or security upgrade, etc.
Step 2: Detection of false positives
This step consists of detecting false positives. If it’s a false positive case, then the failover process need not be triggered.
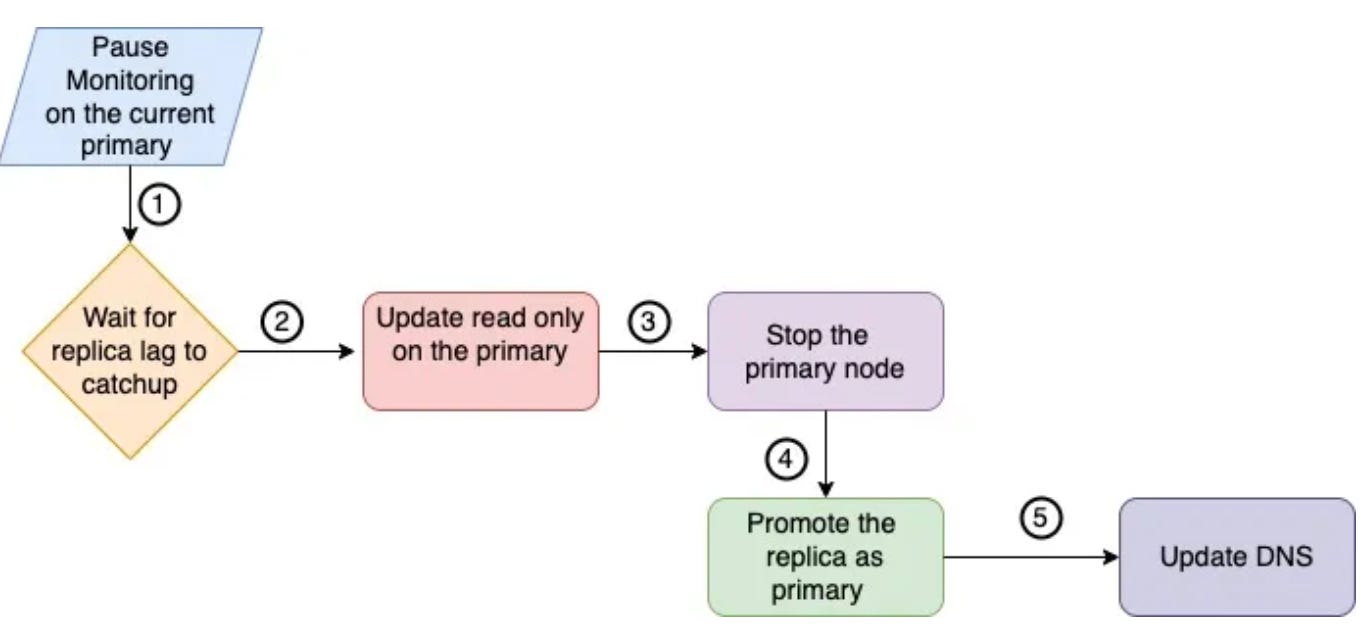
Step 3: The failover
This step consists of performing the actual failover process. Here’s a brief overview of what happens behind the scenes:
Step 4: Service Discovery
ALTAIR uses DNS(domain name-server) for service discovery. Clients use DNS to find the primary instance that translates to an IP address. After a successful fail-over, ALTAIR updates the DNS for the new primary instance and client applications start using the new primary without restarting.
Note: ALTAIR manages the MySQL clusters with the primary replica configuration where all the replicas are asynchronously copying data from the primary. Due to async replication, zero data loss cannot be guaranteed. Thus, Flipkart provides managed TiDB as a solution for all those services that cannot tolerate data loss.
The split-brain problem
Apart from what we discussed above, there is a very interesting problem that Flipkart’s blog talked about and I would like to highlight here is the split-brain problem.
Imagine the following situation:
Initially, all clients are connected to a primary instance.
Due to a temporary network failure, a few clients are unable to connect to the primary instance.
The monitoring component(monitor and orchestrator) perceives that the primary instance is down and promotes a replica instance as the new primary.
The temporary network failure is resolved and now there are two primary instances accepting writes. Few clients are connected to the old primary and few are connected to the new primary.
This is a fatal problem as we have two primary instances are we are accepting writes in two different databases. Imagine the horror: The Flipkart customer might have placed the order successfully but immediately in the next refresh, they might not be able to see the order in their account history.
An idea about how fatal is this problem: GitHub faced a split-brain issue in 2018 where they accepted writes in multiple data centers. While they restored connectivity in only 43 seconds, they took approx. next 24 hours just to reconcile the data that resulted from the split writes in two data centers.
Thus, it’s absolutely critical to stop the old primary instance before promoting a replica instance as the new primary. If ALTAIR is not able to make sure that old primary instance is down, human intervention is required to resolve and do the failover. Flipkart is trying to move away from human intervention in the future.
Kudos to Animesh Agarwal for writing a well-put-out article. 🎉
Book exclusive 1:1 with me here.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Original Blog Post on MySQL High Availability by Flipkart
Video - Scaling managed MySQL Platform in Flipkart by Sachin Japate
nice blog ,
pls make next post about types of updating progress of data update at client side , by using websockets, webhooks, pooling etc in java & angular .
awesome post