
MySQL vs PostgreSQL: Indexing
This article deep dives into what is the difference in indexing in MySQL vs PostgreSQL

Indexes are used to find rows with specific column values quickly. Without indexing, the database would have to read all rows sequentially starting from the first row and scan through all the rows till the end. With indexing, the database already knows the columns in question and can quickly determine the position to seek in the middle of the data file without having to look at all the data. This is much faster than reading every row sequentially.
Indexes, just like the actual data persist in the disk. Most indexes are implemented using the B+Tree data structure. B+Tree is a self-balancing tree data structure that maintains sorted data and allows fast retrieval. B+tree does all operations — Search, Insert, and Delete in O(logn) complexity where n is the number of nodes in the tree.
How does B+tree persist database pages?
B+tree is a tree-like data structure. There are two kinds of nodes in a B+tree:
“internal nodes or non-leaf nodes”: these nodes contain pointers to the other non-leaf nodes or the leaf nodes in the tree
“leaf nodes”: represent the last level of the tree; each leaf node contains the actual row data and represents one single page which contains multiple <key, value> pairs.
For example: refer to the image attached below. In this image, the non-leaf nodes don’t contain the actual data but the leaf nodes contain the actual data <key, value> pairs

Please note that while discussing b+tree in the context of databases, nodes and pages are used interchangeably. So, non-leaf nodes can be referred to as non-leaf pages and leaf nodes can be referred to as leaf pages.
Keys in B+ tree indexes are the column(s) of the table on which the index is created and values are what the databases implement differently.
Let’s take a look at how MySQL and PostgreSQL store these values.
MySQL
In MySQL, there are different kinds of indexes. Let’s take a look at some examples
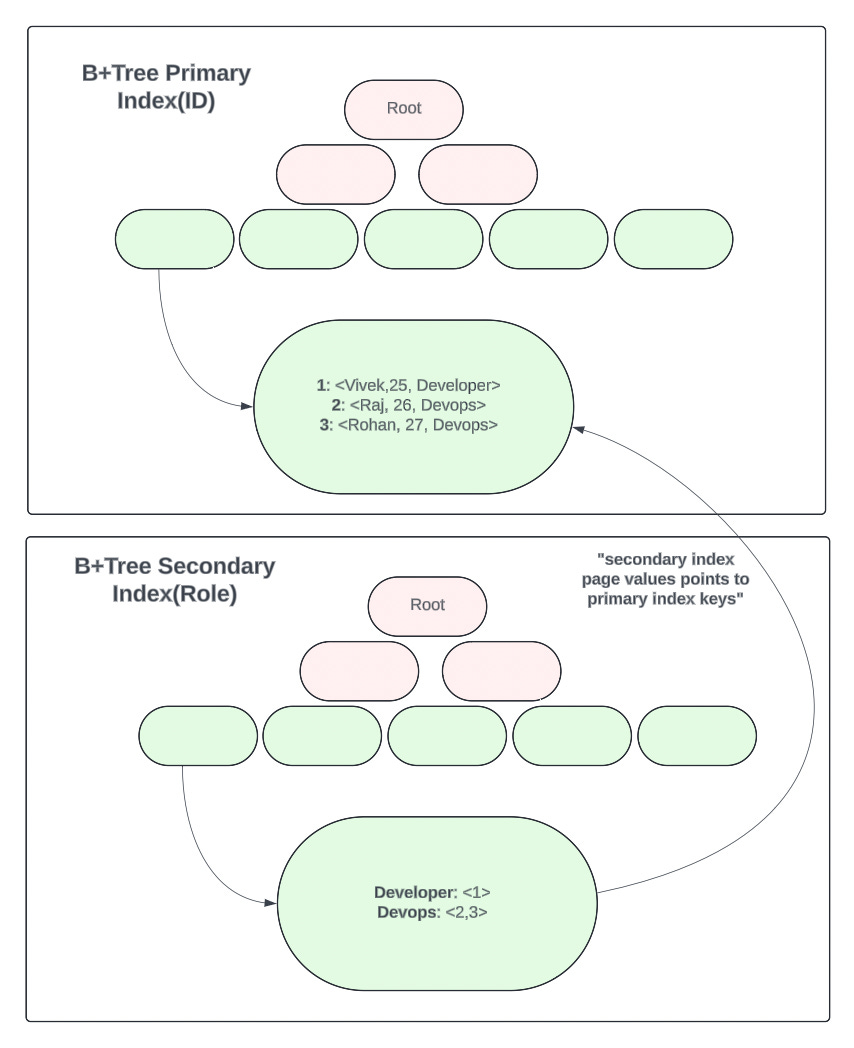
Primary Index: In the case of the primary index, the “value” is the full row record consisting of all the column values. Thus, when you query your database using the primary key, it internally finds out the page/node where the key lives and then returns the value which is the full record. Thus, there is no additional I/O required for fetching other columns.
Secondary Index: In the case of a secondary index, the “value” is the pointer to where the full row really lives. Thus, the value is the primary key itself. Thus, when you query your database using the secondary index, it first figures out the leaf page of the secondary index, and then using the pointer to the primary key, it finds the full record.
A primary index is created on an attribute that is unique across all records. It is a must to have. If you don’t define your primary key while creating a table, one is created for you. A secondary index is created on one or more columns. The benefit of the secondary index is to group similar categories of data which is accessed more frequently and thus reduces the time to find that data.
For example, consider a `User` table that has `name`, `age`, and `role` attributes as columns. The following images represent how primary and secondary indexes will be persisted in the disk.

PostgreSQL
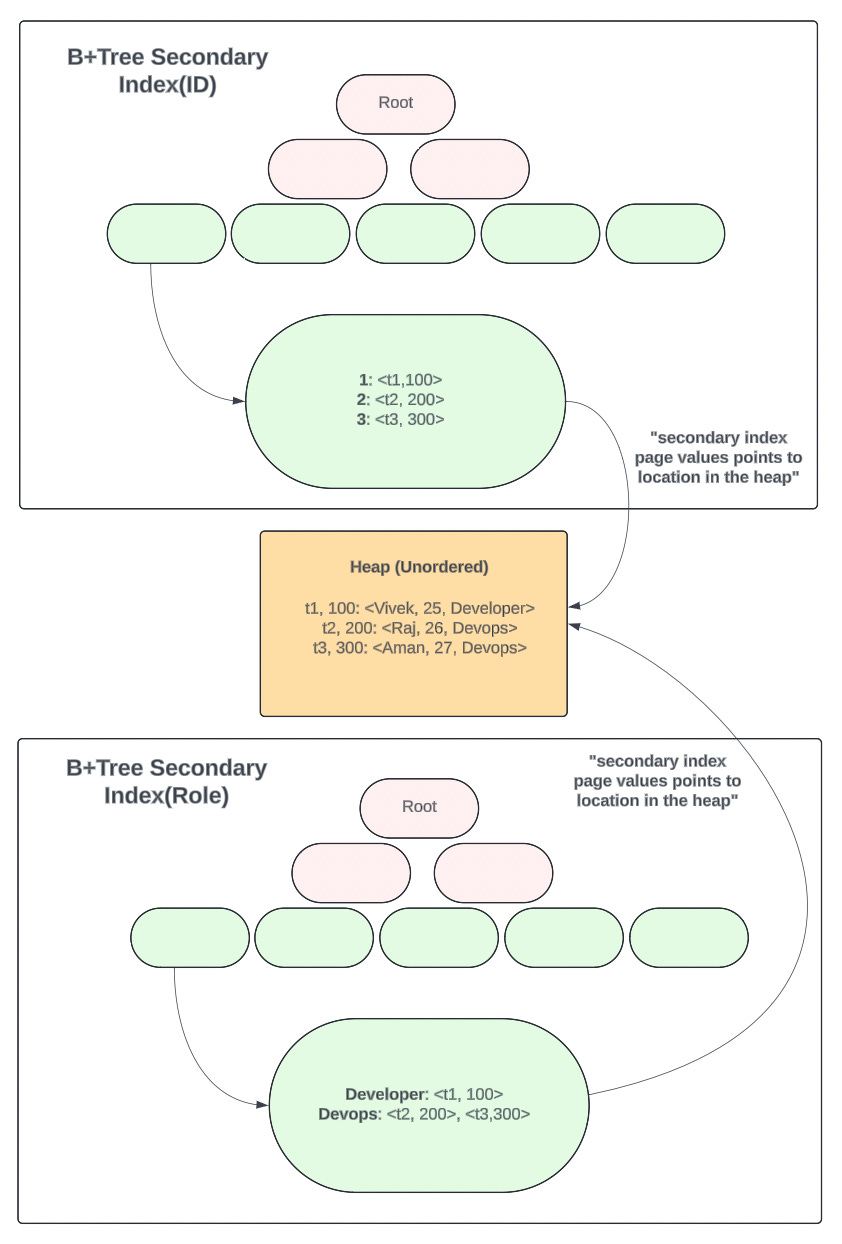
Most of the PostgreSQL indexes use B-tree: a lighter version of B+tree for managing data. Unlike some systems, PostgreSQL doesn't have a primary index. All indexes, including those used for searches, are secondary. They point to internal identifiers (tuple IDs) within the actual data storage, which is called the heap (also persisted in the disk).
But here’s the interesting part. Updates and Deletes in Postgres are treated as inserts behind the scenes. When you update a row, the system creates a new version of the row with a new tuple ID, while keeping the old one for data consistency (Multi-Version Concurrency Control or MVCC). This is different from MySQL which directly modifies existing data.
So, essentially if our secondary indexes point to only tupleID which is managed by PostgreSQL, then it isn’t enough to locate the latest data because we don’t know on which page that latest data lives. That’s why there is a need to store page number alongside each tupleID to locate the data in the heap. The combination of tupleID and page number is called ctid.
Thus, in PostgreSQL, there are two lookups required to fetch the actual data, no matter what index you build:
I/O for Index Lookup: The first I/O operation is used to access and navigate the chosen index structure. This helps PostgreSQL identify the relevant entries in the index that points to the ctid(s) in the heap structure.
I/O for Data Retrieval: Once the index search is complete, PostgreSQL uses the information obtained from the index (often ctid - combined tuple identifier) to locate the specific page(s) in the heap where the actual data resides.
The following image represents the above-discussed case for PostgreSQL:
That’s it, folks for this edition of the newsletter. I enjoyed exploring the indexing in both of the databases. Hope you enjoyed it reading as well. I will publish more editions on comparison between the two databases.
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here.
Resources
Postgres vs MySQL by Hussein Nasser
B+Tree index structures in InnoDB by JeremyCole(ex-Google)
How does MySQL use Indexes?
PostgreSQL documentation on indexes
I have a concern as When we update.delete the row data from postgreSQL . AS data is stored in heap doesn't the heap would overflow.