
MySQL vs PostgreSQL: Replication
This post deep dives into the replication implementation of MySQL vs PostgreSQL

This post is in continuation to the series: MySQL vs PostgreSQL. If you have not read them already, consider reading all the related articles here.
A big shout out to the sponsor for this edition who help to run this newsletter for free 🎉
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams who want to speed up their work flows and consolidate their technical assets.
Brief Intro about Replication
In simple terms, copying the data from one node to all the other nodes in a distributed system is called Replication.
But, why is replication important? Replication provides the following benefits:
Improved Performance: Doing replication of the same data across multiple nodes means your system can handle more read requests across multiple nodes, thus reducing the client’s response time.
Data Redundancy: Replicating your data ensures data availability even if a database node fails.
High Availability: In case a node goes down, replicating your data makes sure that there is no data loss and the system remains available to serve the read requests.
and there are many more factors… but let’s park that conversation for now.
Replication in MySQL
As discussed earlier, Replication is all about copying data from one database(primary) to another(replica). The following diagram explains how replication works in MySQL. Let’s break down the MySQL replication and understand using the following points:

1. Binary log dump thread
Replication in MySQL starts with the primary server keeping track of all the changes to its databases, including any form of create, update, or delete operations in its binary log. It is called a binary log because it contains data in binary format, meaning it stores information in a compact, machine-readable format.
This binary log(also called binlog) acts as the source of truth for all the changes to databases in MySQL since the primary server started (let’s discuss this in detail later)
2. Replica I/O Receiver thread
When “START REPLICA“ is issued on a replica server, the replica server creates an I/O receiver thread that connects to the primary server and requests a copy of the binary log. The key thing to note here is that the replica instance pulls the Binlog contents from the primary server instead of the primary server pushing the Binlog contents to the replica.
The replica server reads the updates that the Binlog dump thread sends and then copies them into a local file called: the replica’s relay log inside the replica server. At this point: each replica present in the system has its own file called the relay log which consists of the same contents in the primary server Binlog dump.
3. Replica SQL Applier thread
As soon as each replica copies the data from the primary server, the replica starts replaying the events present in the binlog in its local database server in the same order as it happened on the primary server.
The replica creates an SQL (applier) thread to read the relay log that is written by the replica’s I/O receiver thread and execute the transactions contained in it. Thus, after some time the whole data is copied to the local server instance.
There is a system variable called: “replica_parallel_workers“. By default, it’s 0, so the replica creates the first applier thread for you. But, you can enable further parallelization by manually setting this value to a greater number. When this is done, the replica creates the number of worker threads on the replica equal to “replica_parallel_workers” and one coordinator thread which reads the transactions from the relay log and assigns them to the worker thread on the replica.
Further thoughts on MySQL replication…
Since each replica has its own copy of the binlog copied from the primary server, the replica instance copies the data at its own pace and can start/stop the replication process at its own will without affecting any other replica or the primary server and their respective operations.
The primary server and the replica servers report their status on the replication process regularly so that you can monitor them.
What are the different formats of the Binlog dump?
There are two formats possible:
Statement-based logging: This strategy logs the exact SQL statement coming on the primary server in the binlog dump.
Row-based logging(the default option): This type of logging logs changes in individual table rows to the binary log. Logging the actual changes in the Binlog dump and not the SQL statement itself.
So, it’s important to conclude here, that you can enable both statement based logging and row-based logging in MySQL and both have their advantages/disadvantages. While Row-based logging increases the load on the network(and thus slow) since the actual changed rows are copied to the replica server, the statement-based logging is fast for replication but increases overhead for some user defined functions. For example: SYSDATE() or other functions when fired at different timestamp on primary & replica produce different results.
Replication in PostgreSQL
I highly recommend reading what is Write-Ahead-Logging in PostgreSQL before proceeding further in this section.
At a high level, there are two possible kinds of replication Physical and Logical replication. Let’s understand them better by picking the primary-replica setup:
Physical Replication: The physical replication consists of sending the bytes of data resulting from executing the SQL commands on the SQL server. This type of replication is useful in cases where we need to prepare a new replica with an exact copy of the primary server. In this replication, the replica is forced to copy all the database tables and rows existing on the primary server instance.
As you can see in the below image the actual data bytes resulting after running the SQL commands on databases are copied from the primary server to the replica server The replica server is forced to receive all the data: databases and tables from the primary server. Either it will get all the data copied from the primary server or it will get nothing.
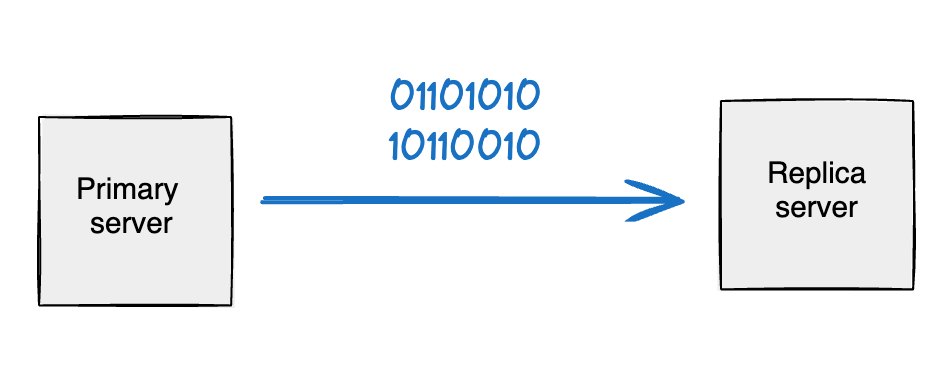
Logical Replication: The logical replication translates WriteAhead Log(WAL) data into logical representations for example SQL statements before sending it to the replica servers. This type of replication provides more fine control of what statements to execute on the replica instance. Thus if we need to copy only one table or a few tables from the primary server to the replica server we use logical replication.
As you can see in the below image the SQL commands are copied from the primary server to the replica server.

In PostgreSQL, the relationship between the primary server and the replica server in the case of Logical replication is defined using the publisher and the subscriber semantics.
Publisher: The database server that captures the database commands and generates the changes to be replicated.
Subscriber: The database server that receives and applies the replicated changes.
Publication: The tables or schemas that should be replicated from the publisher.
Subscription: A configuration on the subscriber that specifies how to receive and apply changes from a publication.
As goes with any pub-sub model analogy, one or more subscribers can subscribe to a publication on a publisher node.
There’s another kind of replication called Streaming replication in PostgreSQL where the primary server generates a continuous stream of changes and sends these change streams to the replica servers. The replica servers receive the change streams and apply them to their local copies of the database, keeping them synchronized with the primary in near real-time.
I could not dive more into it, will try to cover it some other time in future editions. 🧑💻
For both MySQL & PostgreSQL, you can do a lot more with the different number of configurations available in both databases. This article covered some basics but I recommend you to explore more about their replication and share in comments.
That’s it, folks for this edition of the newsletter.
Please consider liking 👍 and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Replication threads: Official documentation by MySQL
Replication Implementation: Official documentation by MySQL
Binary log format: Official documentation by MySQL
Logical Replication: Official documentation by PostgreSQL
Replication: Official documentation by PostgreSQL
PostgreSQL Logical Replication Guide
PostgreSQL Streaming Replication Tutorial
Great read ! Once I had worked on a data auditing service which used to monitor changes in a postgres db using debezium to get the change events. It makes much sense now how that works!