
Sharding v/s Partitioning
This article deep dives into the fundamental difference between Sharding and Partitioning and how they both support in scaling a system.

Brief Introduction
Before we dive deep into Sharding and partitioning, it’s important to understand that these terms are used interchangeably, but they are actually different, so be very specific in your conversations with other people because the interpretation is very different.
A big shout out to the sponsor for this edition who help to run this newsletter for free 🎉 Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams who want to speed up their work flows and consolidate their technical assets.
What is Sharding?
Sharding refers to the process of having multiple machines where each machine can host some dataset. Each machine is called a shard. It does not matter if I am hosting a full dataset in a single machine or splitting it across multiple machines. Sharding is primarily used to scale horizontally and get better performance from the system.

What is Partitioning?
Partitioning involves dividing a single database into smaller, more manageable segments called partitions. These partitions are typically stored within the same database instance or can be stored across multiple database instances. Partitioning is done to primarily reduce the amount of data that needs to be scanned thus improving query performance.
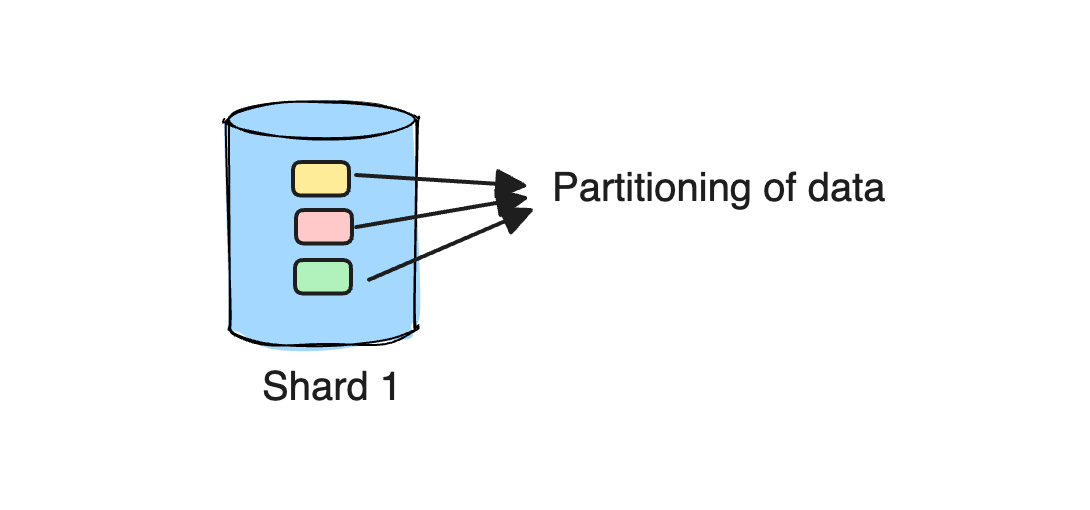
Why do we need Sharding and partitioning?
Let’s say you are building a product. You’re building it from Day 0 and thus you decide to build it using a single machine and spawn the single MySQL process in that machine. Now, you create a database in MySQL and start performing reads and writes on top of your database for your application.

Let’s say your product gains more traction & becomes famous. Now, you are receiving more read-and-write throughput to your database. You realize that CPU is becoming a bottleneck and you are at 90% CPU utilization. To support immediate needs, you consider Vertical scaling your database. This means you install more powerful CPU (higher RAM, higher number of cores, clock speed, cache size) to your machine.

While you will be able to support the immediate needs, you will face this problem again & again in the future as your product gets more & more famours. But, you won’t able to solve it everytime using Vertical scaling because there’s a physical limitation to how much you can vertically scale your machine or CPU. You cannot keep on adding resources to your single machine.
That is why, you would have often heard that truly scalable systems need database sharding i.e. add multiple database servers for a product. By adding multiple servers, we divide the incoming load onto different machines and thus get a better throughput from the system. It does not matter if we store all of the data in a single machine or subset of the whole dataset: that is altogether a separate problem.
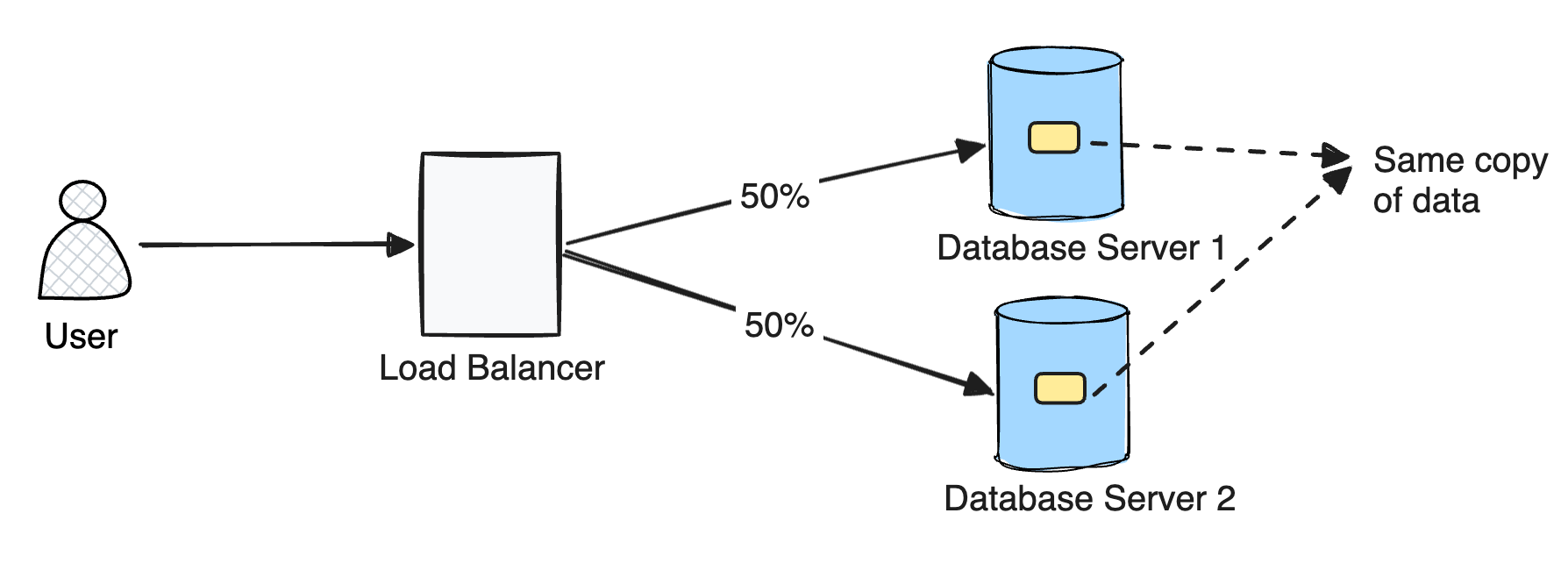
Now, Imagine this situation: What happens when the data in our database becomes so huge that your query performance degrades? Let’s say for every read query, the query is performing a full database scan and is spending a lot of time in computing the output. This query degradation & high latency would be surfaced to the client and you could end up losing business for your product.

You would have to resort to only one option: Split your data into multiple partitions logically in such a way that the query need not perform full database scan. That’s why, we need partitioning in our system as depicted from the image below.

Sharding and Partitioning go hand in hand. They make a system truly scalable for the future needs. I hope it’s clear till this point that Sharding is at database server level while partitioning is at data level.
Different Strategies for Partitioning
Broadly speaking about SQL databases, there are two different strategies on how to partition your data: either partition it based on rows or based on columns.
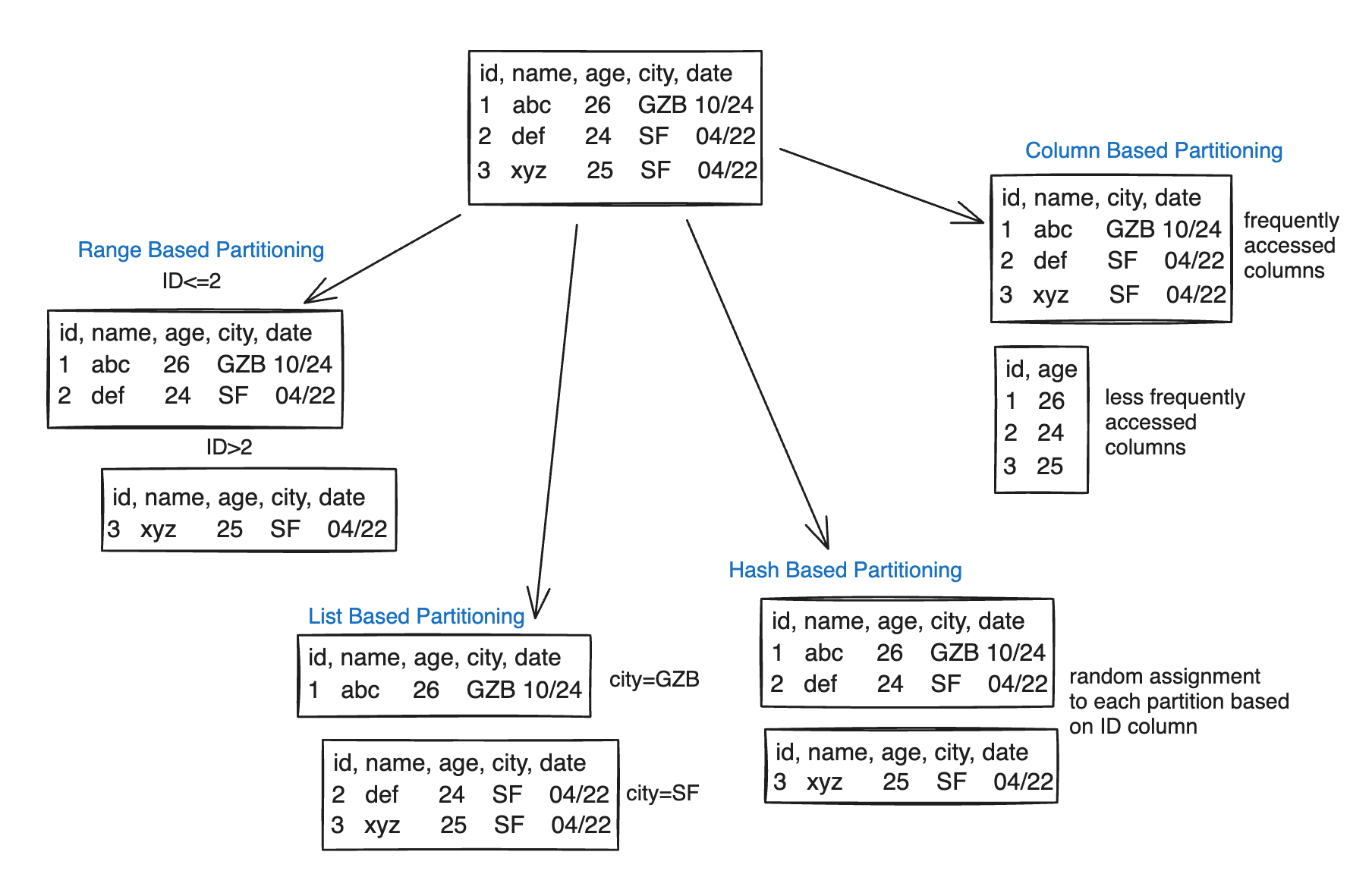
Horizontal Partitioning: In this strategy, data is divided into multiple partitions based on rows. Each partition contains a subset of rows. You can employ different strategies on which row should go to a particular partition.
Range-Based Partitioning: Partitioning based on a specific range of values, such as dates or IDs.
List Partitioning: Partitioning based on predefined lists of values, such as regions or countries.
Hash Partitioning: Partitioning based on a hash function that distributes rows across partitions. This is probably the most popularly used partitioning technique because it distributes data randomly across all partitions and avoids any partition becoming a hot partition (a partition which is facing more reads & writes compared to other partitions)
Vertical Partitioning: Also known as column-level partitioning, this involves dividing a table into smaller subsets based on columns.
Column Partitioning: Storing frequently accessed columns in one partition and less frequently accessed columns in another.
Matrix Visualization
We discussed a lot about sharding and partitioning so far. Let’s put together on how the real world system would look like using a quadrant of Yes and No.

Quadrant 1 <Sharding: No & Partitioning: No> This is our Day 0 of our product where we don’t care about distributing data. Everything is stored in a single database and on a single machine.
Quadrant 2 <Sharding: No & Partitioning: Yes> This is the case where our database has become huge (not yet hit the memory threshold of the box), but it is degrading the query performance. That’s when we partition the data into multiple partitions to avoid full database scans.
Quadrant 3 <Sharding: Yes & Partitioning: No> This is an example of typical primary-replica server setup where the write requests are served by the primary instance and the read requests are served by the replica instance. Full copy of the data is present across Primary and Replica instances and replication happens in the background from primary to replica.
Quadrant 4 <Sharding: Yes & Partitioning: Yes> This is how the real picture looks like in case of highly scalable systems. The data is partitioned so that query performance is not degraded as well it’s hosted on multiple machines to achieve higher throughput from the system.
Special shoutout to Arpit Bhayani 🎉 for preparing this video and giving a matrix representation of Sharding against Partitioning.
That’s it, folks for this edition of the newsletter. Hope you liked this edition. In the future editions, I will answer few more questions around Pros and Cons of Sharding & Partitioning, what are hot partitions and how to deal with them etc.
Please consider liking 👍 and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Database Sharding and Partitioning by Arpit Bhayani
Data Partitioning Techniques in System Design by GeeksForGeeks
Shard(database architecture) by Wikipedia
Partition(database) by Wikipedia
Th final matrix is totally on point, Vivek!
Very insightful 👍!!