
System Design Study: Instagram's Explore Recommender System
This blog deep dives into how Instagram designed their Explore Recommender System and filters out recommendations from billions to only 25.

“Explore” is a feature on the bottom bar of the Instagram app. Once you click on it, you get recommendations for content similar to what you've interacted with in the past.
“Recommendations” is a tough system design problem. Primarily because you would have a lot of data in hand through the user’s history (or from providers). You would need to design the system in a way that can scale for at least millions of users and then recommend personalized content. Only if you recommend the personalized content, the user is going to stick to the platform and keep coming back for more.
You need to have a proper pipeline starting from candidate sourcing to filtering to ranking and then finally displaying to the user. If you’re looking for a starter on how to design recommendation systems, then I highly recommend this system design study: Twitter’s Recommendation Algorithm.
This blog touches upon some key aspects of how Instagram recommends suggestions on the Explore page. Instagram created three pillars for building a recommendation system. Let’s explore them one by one.
Pillar One: IGQL
Instagram created and shipped IGQL - a domain-specific language optimized for retrieving candidates(filtered videos/photos) in the recommender systems. Its execution is optimized in C++, which helps minimize both latency and compute resources.
for example, here is a sample query
user
.let(seed_id=user_id)
.liked(max_num_to_retrieve=30)
.account_nn(embedding_config=default)
.posted_media(max_media_per_account=10)
.filter(non_recommendable_model_threshold=0.2)
.rank(ranking_model=default)
.diversify_by(seed_id, method=round_robin)The good things about this custom language developed are:
High readability even for those engineers who haven’t worked on IGQL.
Multiple queries can be combined to produce an output
We can add a weight threshold to some parameters in the above queries to produce results that result in the best user experience.
IGQL makes it simple to perform tasks that are common in complex recommendation systems, such as building nested trees of combiner rules (algorithms). IGQL lets engineers focus on ML and business logic behind recommendations as opposed to logistics, like fetching the right quantity of candidates (photos & videos here) for each query.
Overall, IGQL makes it easy for developers to play around with data and produce candidates without caring much about how to read and parse the data.
Pillar Two: Account Embeddings
Imagine three Instagram accounts:
@catlover123: Posts pictures and videos of cats.
@kittyworld: Also posts cat-related content.
@vintagetractor: Posts content about vintage tractors.
Let’s say Instagram uses a machine-learning model where each account is represented by a vector in a high-dimensional space. For simplicity, let's use a 2-dimensional space for our example:
@catlover123: [0.9, 0.1]
@kittyworld: [0.8, 0.2]
@vintagetractor: [0.1, 0.9]
Here’s a breakdown of what these vectors might represent:
@catlover123 and @kittyworld have vectors that are close to each other, indicating they share similar content and thus are topically similar.
@vintagetractor has a vector far from the other two accounts, reflecting a different topic.
When Instagram wants to recommend accounts similar to @catlover123 to a user, it can use a distance metric (like cosine distance) to find whether @kittyworld is topically similar or not:
Cosine similarity between @catlover123 and @kittyworld:
Cosine similarity = (0.9 * 0.8 + 0.1 * 0.2) / (sqrt(0.9² + 0.1²) * sqrt(0.8² + 0.2²))
This yields a high similarity score, indicating that these accounts are similar.
Cosine similarity between @catlover123 and @vintagetractor:
Cosine similarity = (0.9 * 0.1 + 0.1 * 0.9) / (sqrt(0.9² + 0.1²) * sqrt(0.1² + 0.9²))
This yields a low similarity score, indicating that these accounts are not similar.
Based on these embeddings and similarity scores, Instagram can recommend @kittyworld to users who like @catlover123, as both accounts are topically related. This way, account embeddings help create a personalized and relevant recommendation system.
So, the question arises: why do we need to have account embeddings? Let’s understand more about this.
The Problem: Categorizing a Mountain of Content
Imagine a library with billions of books on every topic imaginable in the whole world. Traditionally, libraries use a catalog system to organize books by category. However, if we try to apply the same strategy for Instagram's Explore feature i.e. categorize all the content out there on the platform into different categories, this wouldn't work well because:
Massive Variety: There are countless interest communities on Instagram, with topics as specific as Devon Rex cats or vintage tractors.
Constant Evolution: New trends and interests emerge all the time, making it hard to keep a categorization system up-to-date.
The content variety on the platform is HUGE
Content-based recommendation models, which analyze individual posts, struggle with this level of diversity.
The Solution: Focusing on Accounts, not Posts
Instead of analyzing each post, Instagram's Explore leverages the power of accounts.
Accounts as Communities: Instagram has a wealth of accounts dedicated to specific themes. Following an account suggests an interest in that theme. So, Instagram tracks accounts that you’ve interacted with to find similar accounts for recommendation.
Account Embeddings: Instagram creates "embeddings" for accounts. These capture the topical essence of an account based on the content it posts and the users who interact with it. These embeddings are further used to capture the similarity between multiple accounts.
How to build Account Embeddings? Imagine each user's interaction history (likes, follows) as a sentence. Account IDs become the "words" in this sentence. Tools like ig2vec (inspired by word2vec) analyze these "sentences" to understand the relationships between accounts
Both ig2vec and word2vec are embedding techniques, but they target different types of data.
word2vec: Focuses on words. It analyzes a large corpus of text (like books or articles) to learn the relationships between words. For example, "king" and "queen" might have similar vectors, while "king" and "car" might have very different vectors.
ig2vec: Focuses on accounts. It's inspired by word2vec but is specifically designed for Instagram. Instead of analyzing words, it analyzes user interactions with accounts (likes, follows)
word2vec helps understand the meaning of words in text, while ig2vec helps understand the thematic connections between Instagram accounts.
Pillar three: Ranking (distillation)
After identifying relevant accounts with ig2vec, Instagram needs to rank these accounts to keep the content fresh and engaging. Evaluating numerous media pieces through deep neural networks for each scroll action on the Explore page is resource-intensive. To manage this, Instagram introduced a ranking distillation model.
This model is lightweight and trained to approximate the main model (which is a more complex ranking model). Instagram feeds the history input and output data to this lightweight model to filter out some candidates and then only top-ranked candidates go to the next stage.
Now that three pillars(Utilizing IGQL, account embeddings, and distillation) are built for recommendations, it’s time to effectively combine them.
The “Explore” recommendation system is divided into two parts: Candidate Generation(Sourcing) and Ranking Candidates.
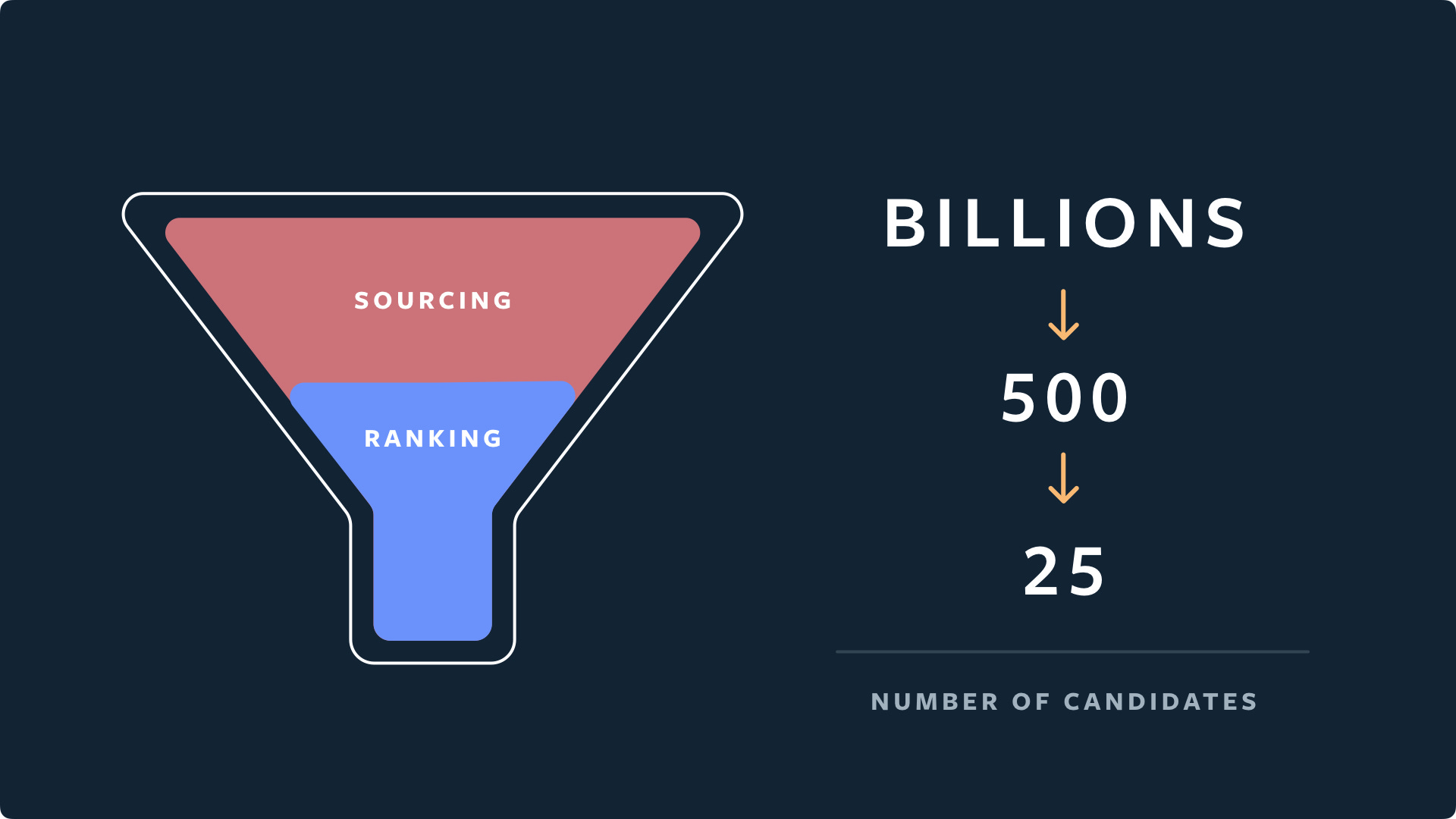
1. Candidate Generation
Firstly, Instagram starts with accounts you've interacted with (liked, saved content from). These are like starting points for your interests. These are called seed accounts. People engage with Instagram accounts and media in various ways (e.g., follow, like, comment, save, share) and across different media types (e.g., photos, videos, Stories, Live). Using (1)IGQL, Instagram constructs various candidate sources through different IGQL subqueries. This process allows Instagram to identify tens of thousands of eligible media candidates for an average user.
Then, using (2)account embeddings, Instagram finds accounts similar to these seed accounts and identifies the media they posted or engaged with.
To ensure recommended content is safe and appropriate for a global audience, Instagram filters out policy-violating content, misinformation, and spam using various signals and ML systems. For each ranking request, Instagram identifies thousands of eligible media, samples 500 candidates, and sends them downstream to the ranking stage.
2. Ranking Candidates
With 500 candidates available for ranking, Instagram uses a three-stage ranking infrastructure to balance relevance and computational efficiency:
First Pass: The (3)distillation model, with minimal features, mimics the other two stages and selects the 150 most relevant candidates.
Second Pass: A lightweight neural network with a full set of dense features picks the top 50 candidates.
Final Pass: A deep neural network with dense and sparse features selects the top 25 candidates for the first page of the Explore grid.
To determine the most relevant content in the latter two stages, Instagram predicts user actions (likes, saves, negative actions) using a neural network. Instagram combines predictions of different events using an arithmetic formula, called “the value model”, to capture the prominence of different signals in terms of deciding whether the content is relevant. They use a weighted sum of predictions such as [w_like * P(Like) + w_save * P(Save) - w_negative_action * P(Negative Action)]. If, for instance, they think the importance of a person saving a post on Explore is higher than their liking a post, then the weight for the save action should be higher.
To ensure a diverse Explore feed, Instagram penalizes posts from the same author or seed account, increasing the penalty factor for multiple posts from the same source in the ranked batch.
Finally, content is ranked based on the value model score.
That’s it, folks for this edition of the newsletter.
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here