


System Design Study: Netflix's adoption of Service Mesh
This article will deep dive into how Netflix adopted service mesh

History about Netflix
Netflix was fully running on AWS in 2010. Back then, for inter-process communication between services, they wanted the following things out of their system:
A richer set of features that a mid-tier load balancer typically provides such as layer 7 load balancing, session persistence, monitoring, analytics, etc.
A solution that can work smoothly in a dynamic cloud-based environment where nodes are coming up and down and services need to quickly react to changes and route around failures.
For these features, they built the following tools:
Eureka: Eureka solved the problem of how services discover what instances to talk to.
Ribbon: This tool provided the client-side logic for load-balancing, as well as many other resiliency features.
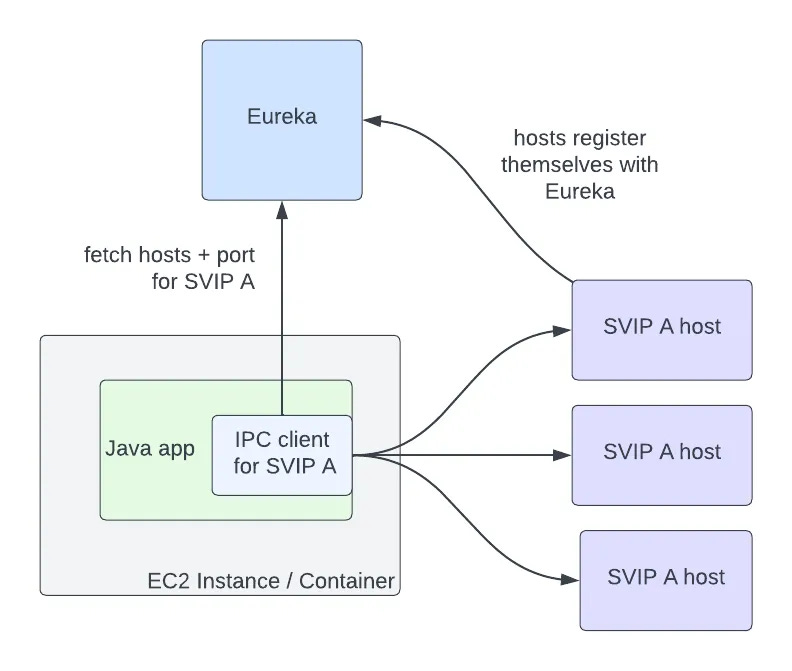
A typical service-to-service communication using Eureka and Ribbon can be interpreted as the following steps:
Every service instance needs to register itself to Eureka i.e. on which IP and port they are running.
When a Java app client needs to connect to service A, then it would call Eureka asking for the list of IP addresses and ports for service A.
Then, the Java app client would establish communication with service A using any IP and port and then exchange data with service A probably using the client-server model.
Please note that Ribbon is installed in every service instance as a daemon that manages the smart traffic routing for equal load distribution which is out of scope for discussion in this blog.
Cons of the Old Architecture:
While the above architecture lasted more than a decade at Netflix for inter-services communication, Netflix faced the following problems:
In this case, Eureka is a single point of failure. If Eureka goes down, then service instances won’t be able to register themselves to Eureka for Service Discovery. Thus, the Java app client can continue to talk to service A instances unless they go down and the connection is broken after which new instances of service A cannot be discovered.
Netflix uses multiple ways like REST, GraphQL, and gRPC to communicate between services. Thus, for every service-to-service communication, three clients are required.
Netflix is not limited to Java anymore but also supports node.js and Python. Thus the clients are language-dependent. Every service will write the client in their independent choice of language which makes it harder to provide support for all the client connections across all the services.
Lastly, Netflix developers need more features for service-to-service communication which should be abstracted out of the service. For example: rate limiting, circuit breaking, etc.
Since Netflix started supporting many more features in more languages in more clients, that’s when they realized they needed a single, well-tested implementation of all of this functionality, so they could make changes and fix bugs in one place and it would be reflected in all other places.
Enters the solution: Service Mesh
Basics first: What is Service Mesh?
If you have worked in a microservices architecture, you know that you need to write some logic in your service to communicate with another service. For example, if service A wants to communicate with service B, then service B’s host and port are mentioned in the configuration files of service A. Then, service A needs to write some logic for establishing an HTTP connection.
The problem is that this way of managing microservices is not scalable. If your ecosystem consists of hundreds of microservices, then each service would have to write its own logic for establishing connections, monitoring, tracing, etc. which is error-prone.
We need a centralized solution that provides all these facilities into a single box and can be used as a plug-and-play for each microservice in our ecosystem. That’s what service mesh is meant for.
A service mesh is a software layer that handles all communication between services. It abstracts out the logic for establishing connections between services, monitoring, logging, tracing, and traffic control. It’s independent of each service’s code and can be attached to any service.
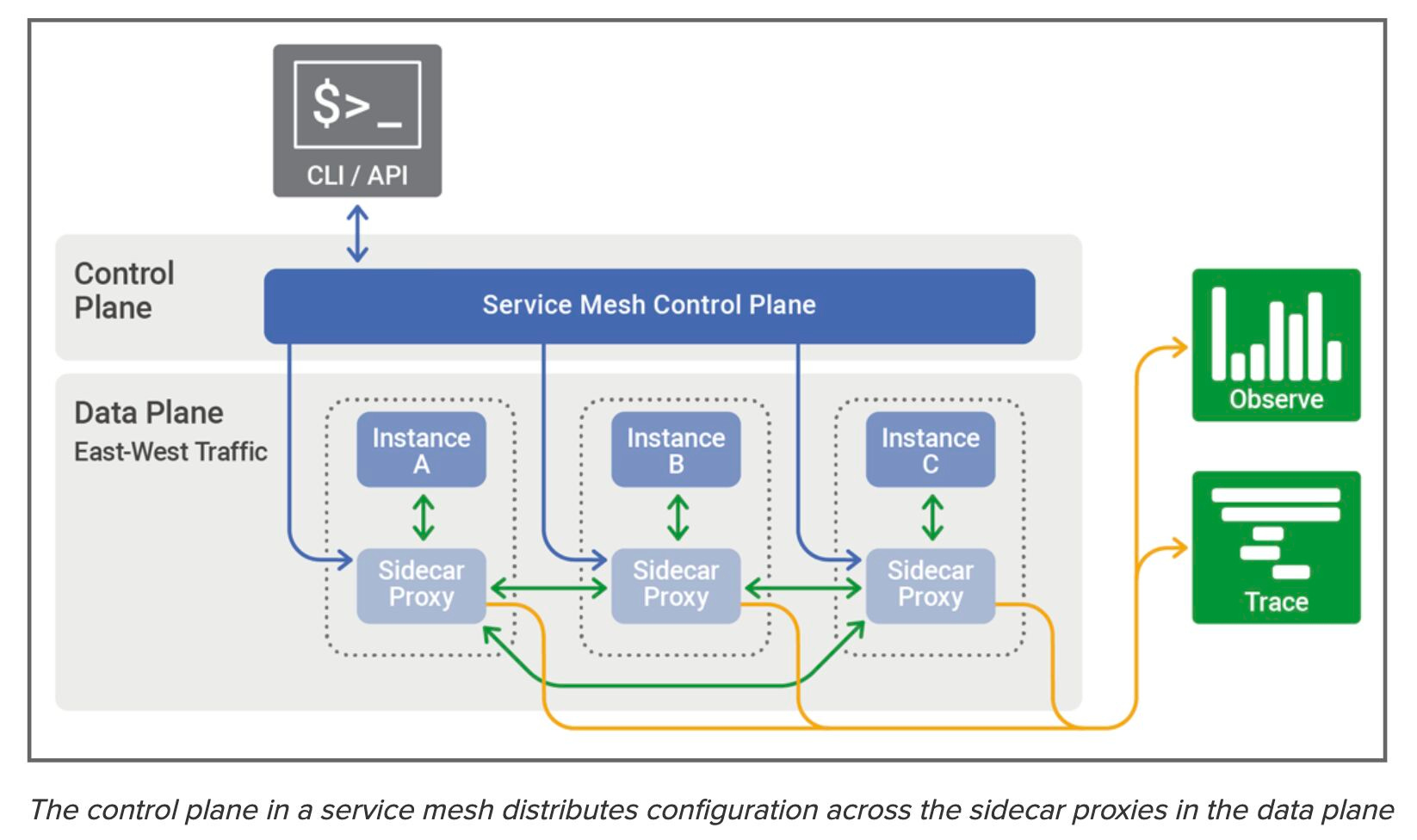
The Service Mesh has two parts associated with it:
Control Plane: This is the brain of the whole service mesh. The control plane specifies the various settings such as timeout, rate limiting configuration, load balancing settings, etc. All the configurations from the control plane are communicated to the date plane.
Date Plane: This is where a sidecar proxy is running alongside every instance of the service and performs various functions such as monitoring, tracing, actual load balancing, routing to target service, etc.
Let’s take a look at how Netflix adopted Service Mesh!!
Netflix adopted Envoy Proxy
Netflix adopted Envoy Proxy for their service mesh use case. It’s a product used at a high scale in the industry with many critical resiliency features. At the time of migration from old architecture to new architecture, they kept in mind the following things:
Need to support backward compatibility at all times.
Automate the migration and make it seamless as much as possible.
Keeping the above two requirements in mind, Netflix tried the possible ways for generating the Envoy config which would represent the inter-process communication:
Ask developers: Netflix thought of asking developers to manually generate an Envoy config for each of their services. This solution isn’t error-proof completely because developers at times don’t know which service they are interacting with while using some external libraries or SDKs.
Auto Generate Envoy config based on the service call graph is feasible but not scalable for new service additions. In that case, developers would have to interrupt and edit the Envoy config manually. This defeats the goal of automated migration.
Due to the above problems, this led to the discovery of something very beautiful called: On-Demand Cluster Discovery.
Btw, Envoy Proxy is very popular. It’s being used at big tech companies like Airbnb, Google, Amazon, Microsoft, Dropbox, Netflix(obviously), and many more…
Netflix’s New Architecture
After the integration of Envoy to Netflix’s stack, the new architecture for service-to-service communication can be interpreted as the following steps:
Client request comes into Envoy
Envoy tries to fetch the list of IP addresses and ports for the target service. If that list of IP addresses and ports is already known, jump to step 7 for the rest of the process.
Let’s say that Envoy does not know about the list of IP addresses and ports, so it pauses the inflight request.
Envoy makes a request to the Mesh Control Plane asking for the list of IP addresses and ports for the target service A. The Control Plane generates a response based on the service’s configuration and Eureka registered information.
Envoy gets back the list of IP addresses and ports for target service A
Client request unpauses
Envoy handles the request as normal: it picks any IP address and port using a load-balancing algorithm and issues the request

Pros of the New Architecture
Two big advantages:
The new Service Mesh adoption is language-agnostic and connection-agnostic for the services in the ecosystem. Envoy as a side-proxy can run in any language independent of the attached service. We just need to support multiple connections in the side-proxy Envoy and it would be inherently supported for all services.
The new architecture supports the two adoption constraints: backward compatibility and automated migration.
Cons of the New Architecture
There’s a downside to fetching this data on demand: this adds latency to the first request. Since Netflix is a popular OTT, the latency addition is too sensitive and some service owners are not happy with this additional latency overhead. For these cases, either the service owners need to predefine the Envoy configuration or they need to warm up the connection before making the first request. Netflix also considered pre-pushing the dependent configurations to the Envoy proxy based on a service’s usage historical patterns.
Conclusion
Overall, the reduced complexity in the system justifies the downside for only a small set of services. My personal takeaway from this blog is that don’t try to reinvent the wheel. Netflix was fine solving a problem for Service Discovery using Eureka and Ribbon. But, when they hit a roadblock, they found a third-party solution and quickly jumped into it and integrated it with their tech stack with backward compatibility. That’s a great thing to achieve in tech companies.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here.
Resources
Netflix’s Zero Configuration Service Mesh with On-Demand Cluster Discovery