


System Design Study: Node Coordination System by Flipkart
This article deep dives into the internals of a blog: node coordination system by Flipkart

Flipkart is a big e-commerce website. People come to Flipkart and search for their desired product in the search bar. As with any type-ahead search functionality on other websites, a dropdown opens up providing suggestions to the user.
Whenever you search for any product on Flipkart, the underlying search in the backend service is usually powered using index clusters (say ElasicSearch) that are designed for faster retrieval of data.
Flipkart has a Near Real-time data store that ensures that systems are updated promptly with recent changes and deliver up-to-the-minute user experience. This means that everytime a product price, inventory, or any other associated attribute is changed, it should be reflected almost in real-time to the end user.
Current Architecture
There are various components involved in the current architecture of the Flipkart’s search index cluster:
Solr: this indexes the product entities
NRT: this is a near real-time store that holds listing attributes related to the product
Leader-follower: there is a single leader node that takes care of all the write operations while the follower node manages the read operations.
Replication: each follower node replicates the data from the Leader node to ensure real-time synchronization between leader and follower nodes.
A single product can have multiple sellers offering it for purchase in the marketplace. The entity that captures the seller-specific details & attributes of a product is referred to as a ‘listing’
Existing Replication Strategy
For replication, Flipkart has scheduled a cron job for every follower node. The cron job takes the responsibility of orchestrating the replication process at scheduled intervals.
When the cron job gets initiated, every follower node performs the following actions:
retrieves the fresh new segments of the index from the leader node and creates in-memory reverse indexes in the follower node that are optimal for operations like sorting, matching, etc. The reverse index consists of all those listings/attributes which are mostly static in nature.
engages in updating the Near Real-time store that contains the listings/attributes that are dynamic in nature and change very frequently.

What are segments in the Lucene index?
The Lucene index(which comprises the whole data) is split into smaller chunks called segments. Each segment is its own index. Lucene searches all of them in sequence. As documents are written to the index, new segments are created and flushed to directory storage.
Challenge: Reduced System Uptime
The size of the segment determines the speed of the replication. If the segment size of the newly created index is large, then the follower node will take time to load the new segment index, and thus it will affect the reads of a single follower node since the computational power(or resources of the follower node) are shared across multiple tasks. Now, extrapolate this and when multiple follower nodes do replication at same time, the overall uptime of the system will reduce considerably.
Overall, any effort that involves simultaneous copying of a newly created index that has a big size to all the follower nodes will cause an increase in latency, thus affecting the overall uptime of the system and thus affecting customer experience.
So, the problem statement is:
How do we do replication in a way such that our system uptime isn’t affected much?
The solution to the above problem lies in two parts:
Part 1: Rolling Replication strategy
Part 2: Node Coordination
Part 1: Rolling replication strategy
What is rolling replication?
Quoting it from the blog:
“Rolling replication is a technique in distributed systems to replicate data among nodes with minimal disruption. It is valuable in situations where maintaining consistency in data, high availability, and minimal downtime are paramount. This strategy involves selecting a subset of nodes for replication based on a replication factor (p), which is typically a percentage of the total node count. Factors such as cluster size and read traffic patterns influence the determination of p. Once the system identifies the subset, the nodes replicate. As replication progresses on one or more nodes, additional nodes are systematically brought into the replication process, ensuring that only a fraction of the total nodes (p) undergo replication. The diagram below illustrates the rolling replication process.“
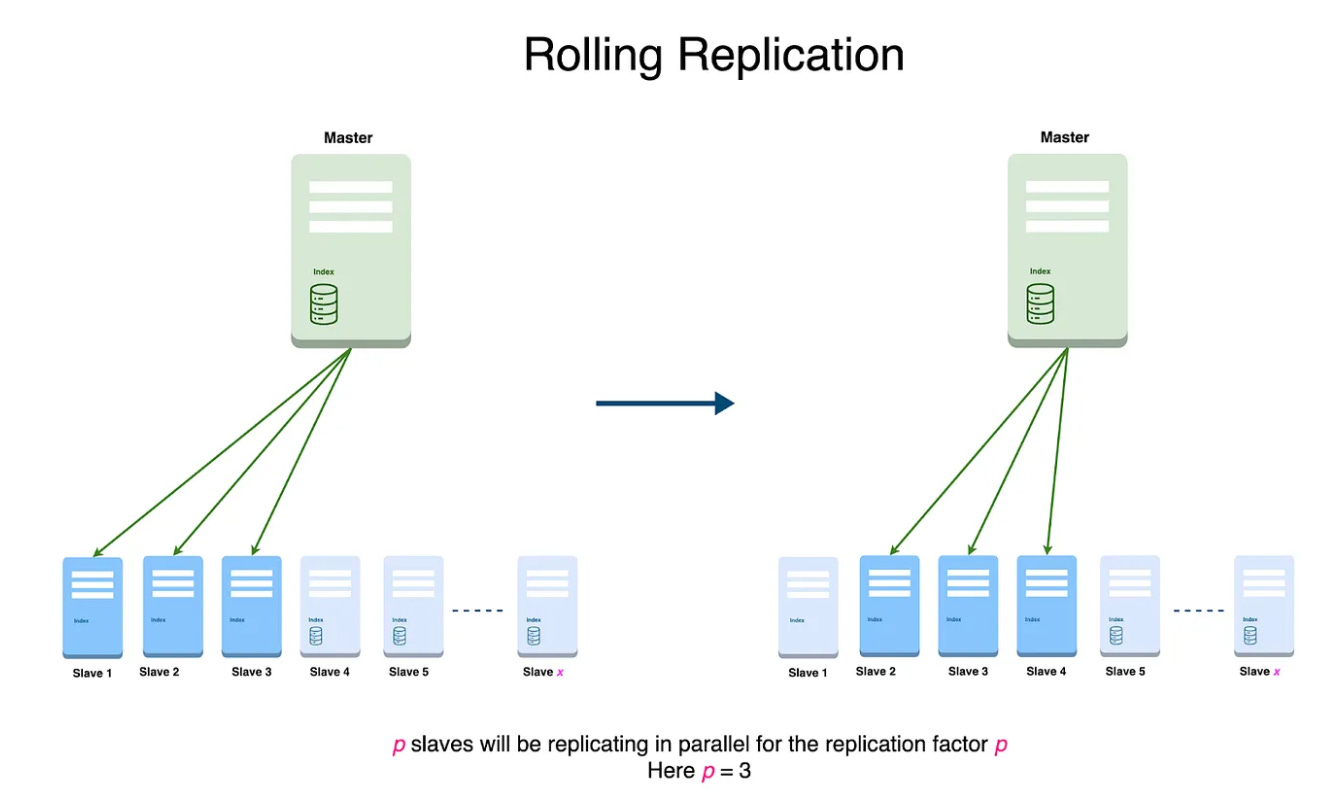
Part 2: Node Coordination
In a distributed system with multiple nodes, there has to be some leader node or some coordinator service that orchestrates the whole replication process and takes care of failure scenarios. Without node coordination, the leader/follower won’t know the status of the replication of other nodes in the system and thus won’t be able to act as a single system. That’s why, Node Coordination is a key requirement for effective replication among multiple nodes. There are various node coordination algorithms such as consensus algorithms that are beyond the scope of this blog.
At a high level, the blog has discussed the following strategies here:
Centralized Node Coordination
This strategy involves installing a single node as the leader or a separate coordinator service for orchestrating the replication process.Search Index Leader as a Coordinator
This category of centralized node coordination involves the master being the coordinator node. It takes two key responsibilities — managing update operations coming to the leader and parallelly managing the rolling replication. On the other hand, follower nodes register themselves to Zookeeper at regular intervals, so that the leader node knows the current health status(active or not) of follower nodes and increases the rollout window of replication accordingly.
While the benefit of this coordination strategy is it uses existing leader and follower nodes, it also puts more pressure on the leader node’s resources for managing both things.
Another Service as a coordinator
Instead of using the leader’s resources, we can install a separate coordinator service which will be responsible for node coordination.
The pros include the isolation of responsibilities and resources of leader-follower nodes only put up for read/writes and replication. The cons include extra development for coordinator service, extra cost for its setup and single point of failure.

Decentralized Node Coordination
In decentralized node coordination, the replication tasks are distributed among the follower instances eliminating the need for a centralized service/coordinator.The pros include no single point of failure and simple architecture. The cons include the potential for complex coordination logic, conflicts without a central authority, and careful resource utilization without overloading any single node.




Final Proposal: After carefully considering all tradeoffs, the company opted for a centralized node coordination system where the leader assumes the role of the leader/coordinator. The leader node is responsible for managing the update operations and then replicating those to the follower node. Although this leader node acts as a single point of failure, it makes sense to do so because when the leader node goes down, the update operations won’t be processed and thus replication should(and would) also stop automatically. This strongly aligns with Flipkart’s requirement of leader-follower architecture.
Conclusion
Well, that’s the majority of the blog! The results of the rolling replication strategy & node coordination resulted in raising the overall system uptime from 99.03% to an impressive 99.93%. The blog also mentions that before initiating replication, precaution is taken to ensure that the number of in-rotation followers(the nodes which are out of the replication window) surpasses a specific threshold so that uptime is not degraded that much.
The blog also considers some failure scenarios and talks about what to do in each of these situations. For example:
Scenario: If a follower fails to respond during replication.
Resolution: Designate the unresponsive follower as unhealthy, and increment the failure count. Investigate and address the underlying cause, which may include network issues, server overload, or other connectivity issues.
Personal take: Overall, this blog has given me a fresh perspective on how to do replication effectively so that the overall uptime of the system is not degraded because of existing resources put to use for replication. I never thought that increasing uptime from 99% would require this level of thinking!
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here.
Resources
Node Coordination System by Flipkart
Sherlock- Near Real-Time Search Store by Flipkart
Near Real-time Indexing by Flipkart