
Case Study: Kafka Async Queuing with Consumer Proxy
This blog deep dives into Uber's Kafka cluster and explains how they built an in-house solution for high throughput called Consumer Proxy

As per Uber’s blog, Uber uses one of the largest Kafka clusters in the world, processing trillions of messages and multiple petabytes of data per day. Almost every critical use case at Uber from the Rider app to the Driver app uses Kafka clusters for streaming data and then storing it in Uber’s Apache Hadoop Data Lake.
Problem Statement
As Uber grew over the years, its throughput in the Kafka clusters grew from hundreds of thousands to millions of messages per second, and here are some challenges that the blog highlights in growing their Kafka clusters:
“Problem 1: Partition Scalability”
Let’s understand this with an example as mentioned in the blog.
Use case: We want to support consumer processing throughput of 1000 messages per second using kafka consumer instances provided that each kafka consumer instance can only process 1 message per second.
“Actual”: Now, for processing 1000 messages per second, we need 1000 Kafka Partitions assuming each partition can deliver 1 message/second. Then, the Kafka consumer instances can process 1000 messages in 1 second.
“Expectation”: The blog puts some generic numbers that each partition in a topic can easily support 10MB per second as the throughput. If we consider 1KB as the average size of a message, each partition can sustain up to 10k messages per second easily.
Thus, the problem here is that Kafka’s partition can support a throughput of up to 10k messages per second(expectation) but our use case is only able to support 1 message per second(actual). Thus, we are underutilizing Kafka’s resources.
If you look from a microscopic lens, the real problem is that the partition’s throughput is actually tied to Kafka’s consumer and its downstream callers’ ability to how quickly they can process a message.
“Problem 2: Head of Line Blocking”
To define this problem statement in a better way, let’s assume the following situation:
Whenever an Uber trip completes, the trip service emits a Kafka event that ingests a message into the Kafka topic (let’s say the topic name is “completed_rides”)
Each Kafka event in the “completed_rides“ topic contains information such as userID, payment_mode, bill_amount, etc. For the sake of argument, let’s consider only “card“ is the supported payment_mode and there are only two card networks: VISA and MasterCard.
Assume that there are two messages in the same partition trip_1 and trip_2. The message trip_1 belongs to the VISA network while the message trip_2 belongs to MasterCard. Also, the assumption is trip_1 message comes earlier in the partition before trip_2 i.e. trip_1 message should be processed successfully before the trip_2 message can be processed.
Now, when the payments service consumer consumes messages from the “completed_rides“ topic, it will either send a request to VISA or MasterCard to charge the user’s card.
Now, there are two sub-problems under Head of Line Blocking, and we will discuss them separately:
(Problem 2.1)Non-Uniform Processing Latency: Suppose that Visa processing latency is elevated. When the payments service is processing trip_1, it will delay the processing for trip_2 as well, even though there is no spike in Mastercard processing latency.
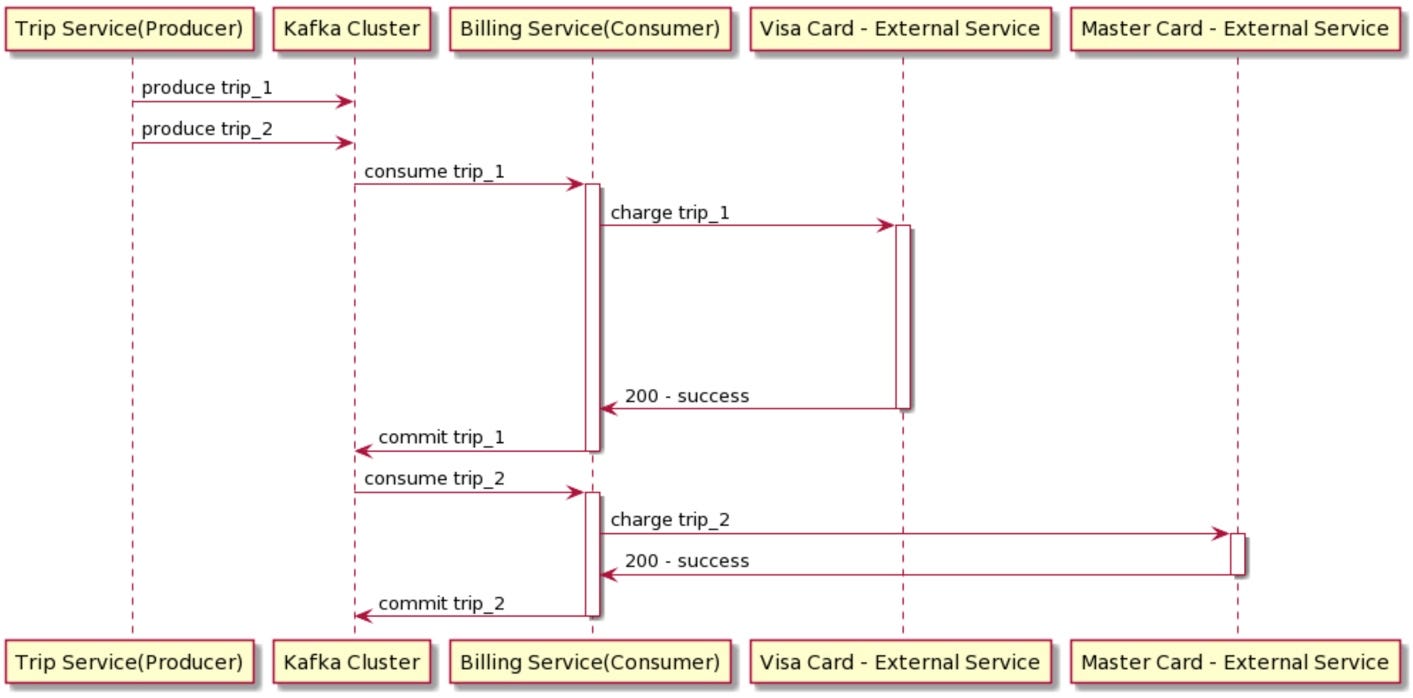
(Problem 2.2) Poison Pill Messages: VISA’s card network is completely down while MasterCard’s card network is up and running
Now, the problem is that MasterCard’s card messages at a higher offset will not get processed if there is a VISA card message in the partition at a lower offset. This is because of the recommended Apache Kafka’s Consumer pattern:
Read a single message from the partition
Process that message
If the message is processed successfully, then all is good. Otherwise, don’t process the next message and keep on retrying to process the current message unless it is processed successfully.
Thus, the consumer would keep on retrying to process the VISA messages but they won’t go through and thus MasterCard card network messages will also not get processed.
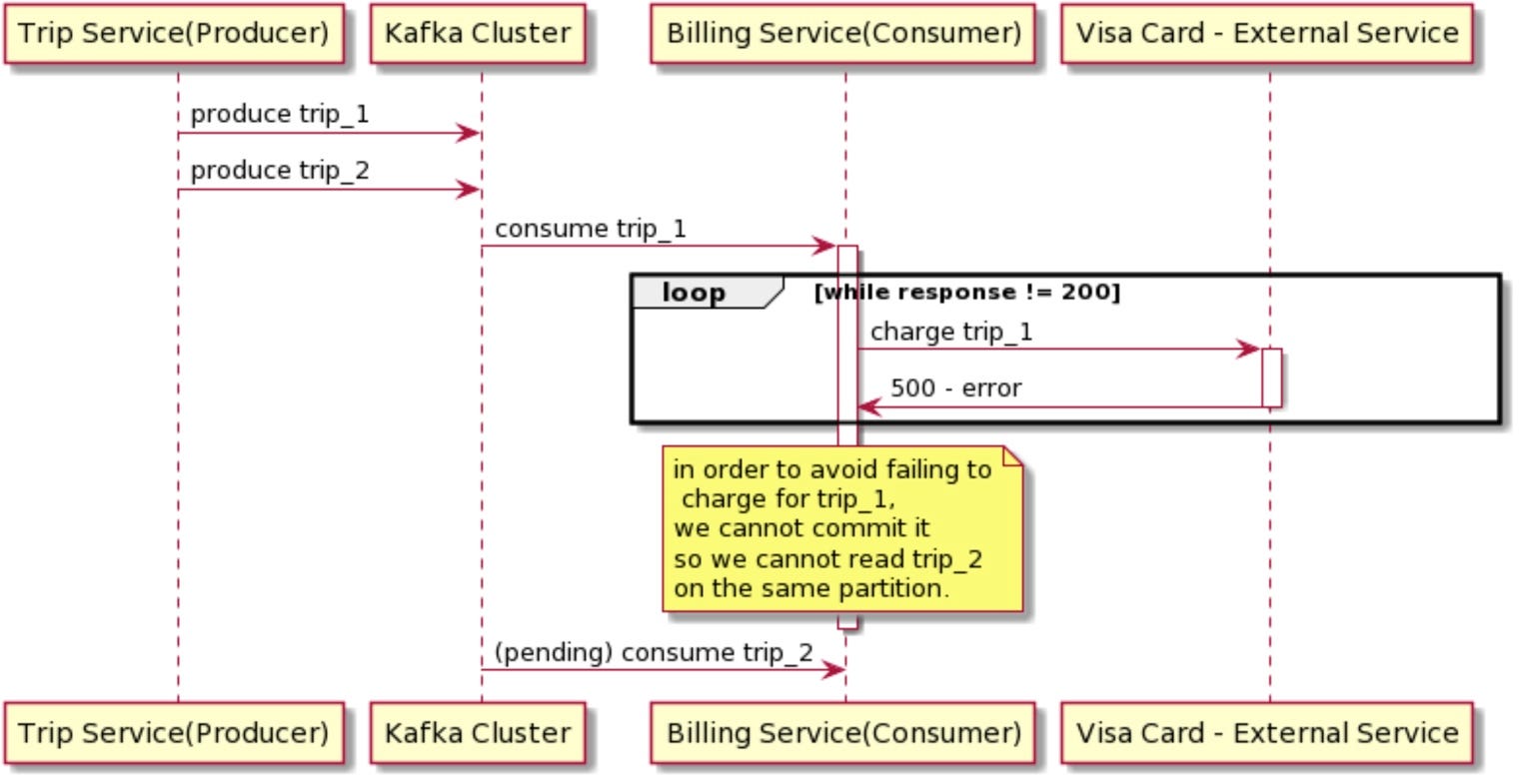
In Kafka’s context, such messages are called “poison pills”. To put it a definition, a poison pill is a record that has been produced to a Kafka topic and always fails when consumed, no matter how many times it is attempted.
To summarize, we have three problems:
How do we get efficient use of Kafka resources i.e. Kafka partition can send data at 10k messages/second but our system’s processing rate might be much slower which will lower the effective throughput of the system.
How do we make sure that all messages in the Kafka cluster are processed at a uniform latency irrespective of any specific outages that affect only some subset of messages?
How to deal with poison pill messages that we know won’t get processed at any cost?
So, how do we solve the above problems?
Enters the solution: Consumer Proxy
The Solution: Consumer Proxy
To solve the problem of Partition scalability and head-of-line blocking, Uber introduced a proxy between the Kafka cluster and Kafka consumer instances.
At a high level, Uber’s Consumer proxy follows the below steps:
Consumer Proxy fetches the messages from the Kafka cluster.
Then, the consumer proxy sends the message over a gRPC endpoint exposed by the consumer service.
The consumer instances process the message
Consumer proxy receives the gRPC status code
Then, the consumer proxy aggregates the processing result for all the messages that were fetched in a single batch from the Kafka cluster
Then, the consumer proxy commits the offsets to the Kafka cluster

Now, let’s take a look at how Uber solves the above two problems individually:
Problem 1: Partition Scalability
Solution 1: Parallel processing within Partitions
With the high level architecture described above, the consumer proxy node can consume a single partition and send messages within a partition parallelly to multiple consumer instances. If you remember earlier, we were limited by the fact that the second message in a partition cannot be consumed by the consumer service instance unless the first message of the same partition has been processed successfully — this is no more a concern here.
Thus, the throughput is not tightly coupled anymore with partitions and the consumers instances. The partitions can continue to give high throughput and consumer proxy nodes will balance the load evenly across all consumer service instances.
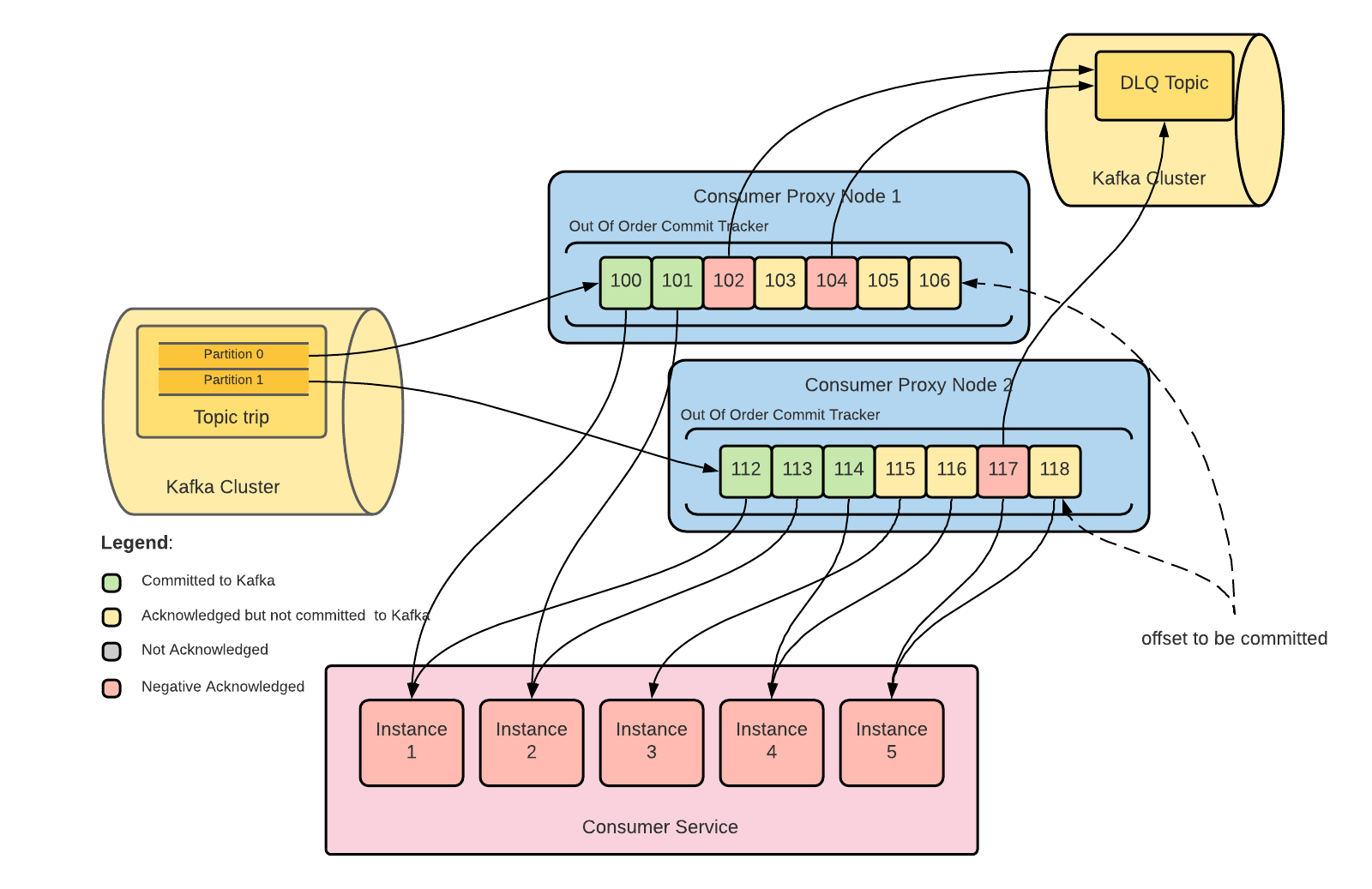
As shown in the below figure, messages 100, 101, 102, etc. can be sent parallelly to multiple consumer instances.

Problem 2.1: Non-Uniform Processing Latency
Solution 2.1: Out-of-Order Commit
The main problem in this context is how to make sure that VISA card processing latency does not affect MasterCard processing latency. We have partially solved this problem using Parallel processing within partitions where we send the messages parallelly to multiple consumer instances but the problem is that we have not yet committed the message to Kafka.
In a Kafka cluster, when we commit an offset, the messages with lower offsets are also marked as committed. In Consumer proxy design, Uber tracks two things:
1) which messages are marked as “acknowledge” (acknowledge is Uber’s way of defining which message is successfully processed by any consumer instance but not yet committed to the Kafka cluster)
2) which messages are marked as committed to the Kafka cluster.
At the end, the Consumer Proxy tracks which offsets have been acknowledged, and only commits to Kafka when all the previous messages have been acknowledged, but not yet committed.

With out of the order commit, the steps are:
The Consumer proxy fetches a batch of messages from the Kafka cluster, inserts them into the out-of-order commit tracker, and then sends them parallelly to the consumer instances.
From the last committed message, once a contiguous range of messages is acknowledged, the consumer proxy commits a new offset to the Kafka cluster and fetches another batch of messages.
This solved our problem of non-uniform processing latency completely. With parallel processing of messages in a partition and out-of-order commit, we can acknowledge all the messages parallelly: probably first for MasterCard messages and then for VISA messages with some time delay.
Possible duplication of messages: When a consumer group rebalance takes place meaning that a consumer gets added or exits, the partitions might get reassigned to a new consumer. Thus, the new consumer instance would fetch all the messages since the last committed offset from the Kafka cluster and this might contain a few messages that were already in the acknowledged state with the previously assigned consumer instance. This can lead to duplicate message consumption. Uber solves message duplication by expecting their services to dedupe the messages before processing them.
Problem 2.2: Poison Pill Messages
Solution 2.2: Dead Letter Queue(DLQ)
Dead Letter Queues can be considered as separate Kafka topics that contain poison pill messages and are intended for retrying the messages later with the consumer instances.
How does it work with DLQ? The consumer services signal the consumer proxy by returning a specific gRPC code which signifies that the message is a poison pill that is non-retryable and should be published to the DLQ(Dead Letter Queue) Kafka topic. Then, the consumer proxy publishes the message to the DLQ Kafka topic and after persisting it successfully, the proxy marks the message as “negative acknowledge”. Then, the consumer proxy commits all the messages to the Kafka cluster if all of them in the contiguous sequence are “acknowledge” or “negative acknowledge”.
Later, as per the team's needs, they can follow either of the two options:
Merge the DLQ: Replay all the messages in DLQ by sending them to consumer service instances.
Purge the DLQ: Discard messages in the DLQ
Conclusion
Uber built this in-house push-based consumer proxy solution, that sends the messages to multiple consumer service instances over a gRPC endpoint. The consumer proxy adjusts message push speed accordingly in response to the gRPC status codes received from the consumer service instances.
Overall, my personal take from this case study is that everything in design has a tradeoff. I never thought that delivery of messages within a partition in an ordered fashion restricted the overall throughput of the Kafka cluster end to end. At the same time, parallel processing of messages within a partition has given me a fresh perspective on processing messages.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here.
It seems like the problem is that kafka's default unit of parallelism is the partition (N consumers are mapped to N partitions enabling N degree of parallelism), but what Uber wanted is parallelism even within a partition.
Wouldn't a much simpler solution be to increase the number of partitions to `numConsumers * numThreadsPerConsumer` and make every consumer thread a separate kafka consumer of its own? I believe this is how the Kafka creators envisioned it to be done.
Another option would be to use Amazon SQS instead of Kafka where there is no concept of partitions and we can simply scale up the number of consumers however we want.
Wouldn't it be simpler to just publish each message type to a separate topic?
This solution is not so simple to monitor - if you have 3 types of messages in one topic, your topic lag isn't very descriptive - you need to go deeper to understand the issue