
What is CAP theorem?
This article deep dives into the popular question: What is CAP theorem and what does CAP-Consistency and CAP-Availability actually means.

Hello readers, I hope you’re doing well!
In this edition of the newsletter, let’s discuss the following topics:
1. CAP theorem: Statement
2. Consistency or Availability?
3. Problems with CAP theorem for Distributed systems
4. Conclusion
CAP theorem: Statement
As per Wikipedia, the CAP theorem (also known as Brewer’s theorem by the author Eric Brewer) states that any distributed database (using multiple nodes) can only provide two of the three following guarantees
Consistency
Every read receives the most recent write or an error.
Availability
Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
Partition tolerance
The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
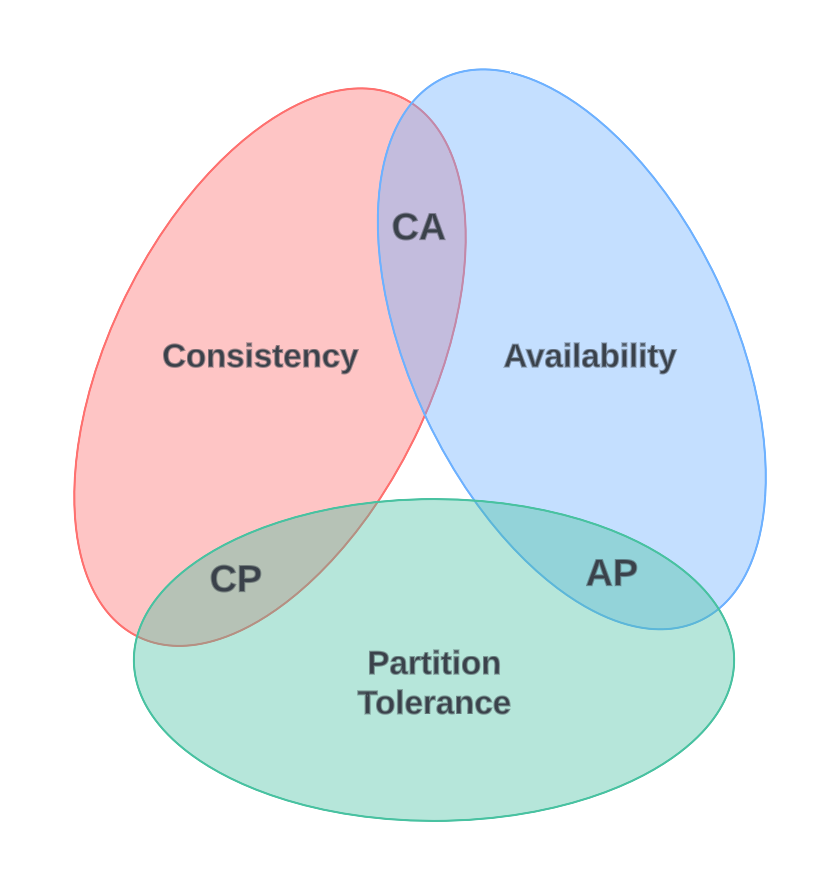
Let’s cut the long story short!
Partition Tolerance: You can’t have a real-world system in which there is no partitioning between your database nodes. The partitioning between your nodes is something you don’t really have control over. It might happen because of running out of disk memory, reboots, crashes, or a broken network.
Since you can’t give up on partition tolerance among the two out of three options, so, another way to state the CAP theorem is:
When there is a partition between your database nodes, you must choose between:
cancel all kinds of requests and thus decrease the availability but ensure consistency(this is an extreme form of consistency i.e. linearizability)
accept and process the requests and thus provide availability but risk inconsistency
Consistency or Availability?
Now, let’s deep dive into what Consistency and Availability actually mean as per the CAP theorem:
Consistency: CAP consistency is an extreme form of consistency (linearizability) that states that even though there are multiple database nodes in a system, when an update comes, it should seem like all database nodes are updated at the same moment, therefore giving the same data to the end users.
[Using an example similar to Martin Kleppmann’s CAP explanation] Imagine that two users User 1 and User 2 are following the live scorecard of the Cricket World Cup finals on their respective phones using the Cricbuzz(Cricket News) app. Imagine this scorecard information is shown to the end users using a database. This database uses a master-slave replication strategy i.e. it has one master for writes and multiple slave nodes for performing reads.
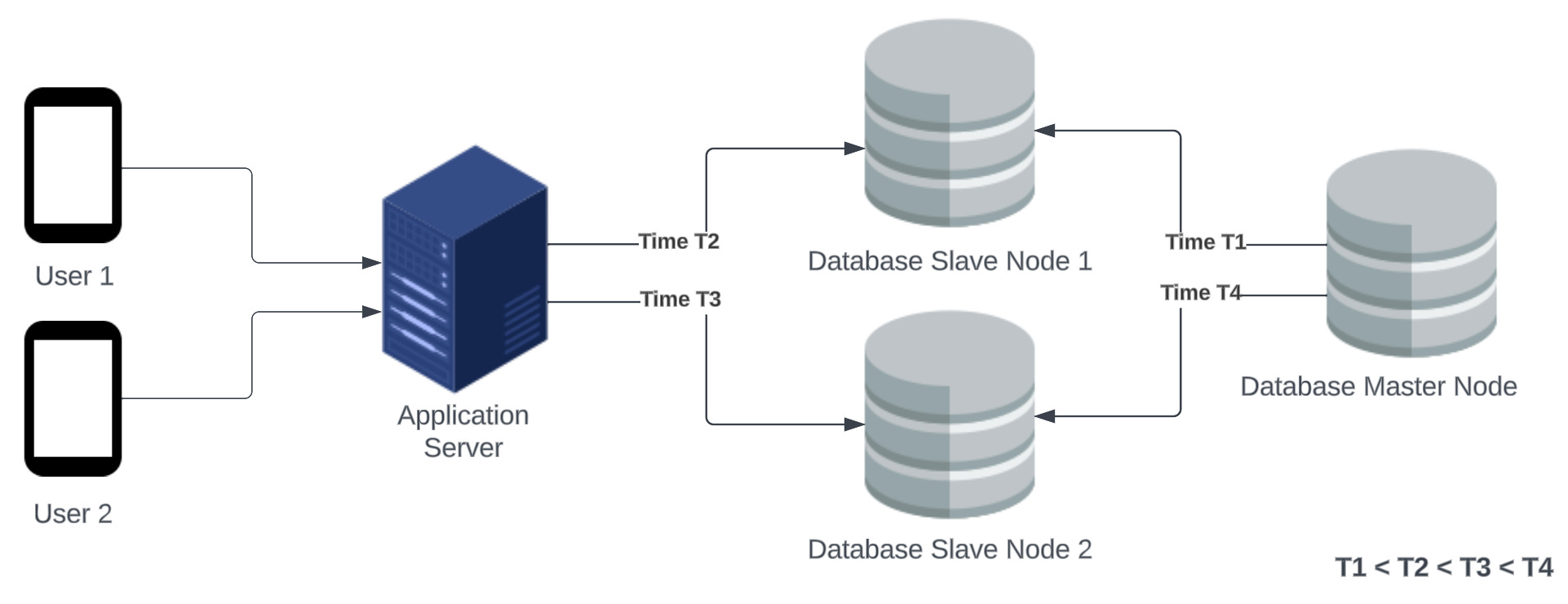
T1 = Time moment when Master node successfully updates the Slave node 1 with latest score
T2 = Time moment when User 1 request to get the latest score is successfully completed on Slave Node 1
T3 = Time moment when User 2 request to get the latest score is successfully completed on Slave Node 2
T4 = Time moment when Master node successfully updates the Slave node 2 with latest score
T1 < T2 < T3 < T4
If two users, User 1 and User 2 request at time T2 and T3 respectively to get the live scorecard, it may very well be the case that their respective live scorecards are different from each other. Why? Mainly because the read requests for User 1 and User 2 were performed by different slave nodes and there is a lag across slave nodes in replicating the data from the master node.
Imagine the amount of disappointment it would cause User 2 if they came to know about the result of the Cricket World Cup finals from User 1, just because there was a lag in the database replication. Thus, User 1 was able to get the final results whereas User 2’s phone would still show that the play is in progress.
To cater to the above problem, you might want to provide linearizability(CAP-consistency) which makes sure to update all the database nodes before accepting further reads and writes requests. So that, User 1 and User 2 would always get the same scorecard at all times.
This strict form of consistency we discussed above is called linearizability and is an expensive guarantee to provide to the end users.
Availability: CAP availability means every request received by a non-failing node in the system must result in a [non-error] response without the guarantee that the response data contains the updates from the latest write.
In the above example of User 1 and User 2, if we let both user requests read from the database slave nodes, our system would give up CAP-consistency (as both users might receive a different scorecard) but our system will be called CAP-available.
On the other hand, if we don’t allow the user requests to read from the database slave nodes until all nodes are in sync, then although our slave nodes have not failed yet they are not available to give a successful response and thus are not CAP-available.
Now that you’ve understood what CAP Consistency and CAP Availability are, let’s deep dive into what are the problems.
Problems with CAP theorem for Distributed systems
The main problem with the CAP theorem is it does not fit or get applied to the systems we are building in today’s world. To summarize the CAP theorem again, we must choose between the following two options:
Linearizability(CAP-Consistency) over CAP-Availability
In a distributed database system, you can choose linearizability over the CAP-availability meaning reject all the reads and writes requests until all the database nodes are in sync with exactly the same set of data.
There might be some nodes who have the latest write and a few nodes who don’t have it yet. Still, the system is not CAP-available because a few nodes that are out of sync and have not failed as such are still not active for returning a successful response.
Problem 1: CAP-consistency (Linearizability) comes at a cost and most systems don’t want that. When you chose linearizability, it means your system is okay to pay the performance penalty i.e. not process reads and writes unless all database nodes are in sync. But, is that the need for most of our systems today? Well, not really. Consider the case of social media platforms, we all know more than hundreds of million users are active daily. It’s completely okay to give up consistency and show posts by a slight delay rather than to give up the availability.
In true sense, availability in today’s world is tied to your revenue. You might be able to manage consistency using some algorithms but low availability directly means losing business.In case of Social Media platforms, losing availability means losing Ad revenue.
As Matrin Kleppman says, Availability in practice does not quite correspond to CAP-availability and Availability as of today should be measured in terms of SLA i.e. how much % of requests we are able to respond successfully.CAP-Availability over Linearizability
All database nodes are available for accepting a request, processing it, and returning a successful response thus CAP-Available but give up on linearizability (the strongest form of consistency) because a few database nodes might be out of sync because of network partition.
Problem 2: CAP-Availability is not a fulfilling metric to judge the system. Let’s say if you have 100 nodes, all of them are active and able to respond a successful response, it means that system is CAP-available, but is that enough? What if it takes around 10 seconds to load the website of your service? That is a nasty user experience. So, the actual requirement is to be available with some desired SLA of 99% but also have P95 latency or P99 latency under desired threshold say 1 second or few milliseconds.
Conclusion
Now that you have understood the CAP theorem and its problems for distributed systems, it looks like it does not fit today’s distributed system because of some major gaps that we discussed above. It’s okay to discuss it because it gives you a perspective of why CAP is not enough and why we need a better tool to measure our distributed systems.
Alternative: PACELC is another theorem, an extension of the CAP theorem. Wikipedia states that in the case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and loss of consistency (C).
Well, I’ll save this discussion in detail for some other day.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. In the upcoming editions, I will share more about the PACELC theorem and discuss how the theorem applies to various distributed systems that we use today.
Resources
Wikipedia - CAP theorem
Original CAP theorem presentation by Eric Brewer
Martin Kleppmann - Please stop calling databases CP or AP
Brewer’s theorem Conjecture
Wikipedia - PACELC theorem