
What is Consistent Hashing?
This article deep dives into the consistent hashing algorithm - what it is and how it's helpful in real-world use cases

Hello readers,
In this edition of the newsletter, let’s discuss the following topics:
1. What is Hashing?
2. What is the problem?
3. The solution: Consistent Hashing
4. Virtual Copies
5. Conclusion
What is Hashing?
In simple terms, Hashing is the process of transforming any input key to some variable-length output value. This output value can be stored or indexed in suitable data structures for performing search operations. This is achieved using a hash function and values generated by a hash function are called hash values or hashes.
We can also use these hash values generated by the hash function to prepare a table also known as a hashtable.
for example: mapping all the domains in the world to any random integer is called hashing.

Let’s go ahead and understand how can we use hashing or hash functions for our real-world use cases.
What is the problem?
Let’s say the problem statement is to support the following two operations with the help of datastore nodes:
SET key value (this should store <key, value> as a pair in the datastore)
GET key (this should return the corresponding value for the input key)
Let’s say, we pick any generic datastore (SQL or No-SQL, it does not matter) for our example. Now, we can support the above two operations using one datastore node. The interaction would look like the image attached below. The server would call the database directly to perform any operation.

The main problem here is that when you’re dealing with terabytes or petabytes of data, you cannot practically fit all of your data onto a single machine. Thus, increasing the datastore node’s memory (Vertical Scaling) won’t help us build a scalable solution.
The other solution is to increase the number of datastore nodes(Horizontal Scaling) and distribute data across the nodes i.e. if you have 600 TB of data and 3 servers, then store 200 TB of data per node.

The problem in the above solution is how to decide which <key, value> should reside on which datastore node.
This problem can be solved by using a Hash function. Use a Hash function for hashing the incoming <key> and take modulo with the number of datastore nodes to determine on which node should the key reside.
For example: If I have 6 <key, value> pairs to store and 3 datastore nodes, using a Hash function will distribute the keys in the following manner.

<Key, value> = <String, String>
Hash() = Hashing function
M = Number of datastore nodes i.e 3 in this example
In the above example, we have 6 keys and 3 datastore nodes, and using a hash function, we were able to distribute the keys uniformly across the 3 nodes. That’s the beauty of selecting a good hashing function. A good hashing function will always produce uniformly random values.
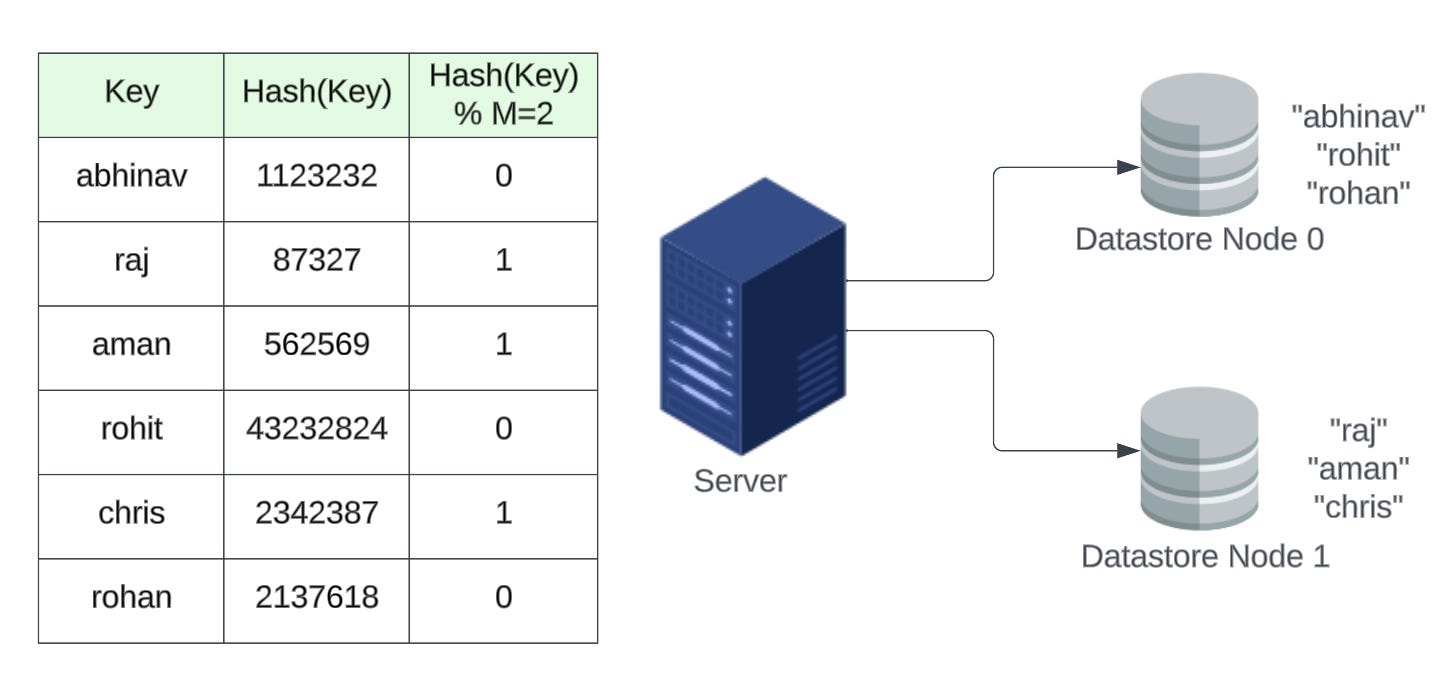
But, wait, there is one more problem, what if one of the datastore nodes, let’s say datastore node 2 goes down?

We won’t be able to fetch corresponding values from the datastore node 2 for the given keys. To make sure, we can perform both operations SET <key, value> and GET key, we need to come up with a new hash function. In this case, we can modify our modulo value i.e. number of datastore nodes from 3 to 2.
Now, using the new modulo value, the redistribution of all the keys would look like:
Similarly, in cases where we can’t add more data to our existing datastore nodes, we are left with no option but to increase the number of datastore nodes. Thus, for storing data on the new node and to ensure a uniform distribution of keys across all datastore nodes, we would have to do a redistribution of the keys. This would look like the below diagram.

As you can observe from the above two diagrams, there is a main problem with the normal hashing which relies on the number of servers for the modulo value.
Every time there is a datastore node added/removed, we need to consider rehashing all the keys present across all of our datastore nodes. This is a super expensive operation in terms of shuffling the whole data.
Thus, it’s not scalable at all in real-world systems where we might deal with peta bytes(10^3 TB) or exa bytes(10^6 TB) of data.
The Solution: Consistent Hashing
We want everything we did previously using normal hashing (storing keys and retrieving them later) with an additional property that almost all keys should be kept assigned to the same datastore node even if other nodes are added or removed. Thus, in short, we want to optimize the number of keys that should be rehashed to other nodes in case of adding/removing datastore nodes.
Consistent Hashing is a scheme where we imagine a big ring consisting of buckets linearly between 0 and [2^32-1]. We are choosing 2^32-1, a big value for our huge hash space because we don’t want to limit ourselves by the number of servers as discussed in the normal hashing. Thus, to reduce collisions and have as much big hash space as possible, we consider 2^32-1 as our modulo but it’s not mandatory, you can choose 2^64-1 or any big number.

Then, we calculate the hashed values of the keys and hashed values of the datastore nodes and place them in the buckets on the ring. For example:

The algorithm to find which <key, value> should reside on which datastore node is using the following steps:
find the Hash of a given key, let’s call it h(key)
locate the h(key) on the circle ring and start traversing the ring in the clockwise direction. The first bucket to encounter which is equal to the hash of any datastore node is the target datastore node on which this key should reside.
So, according to the above algorithm, the keys would be stored on the datastore nodes as shown in the below image.

So, as per our algorithm,
the keys “chris“ and “rohit“ would be stored in the Datastore Node 0 (D0)
the keys “raj“ and “aman“ would be stored in the Datastore Node 1 (D1)
the keys “abhinav“ and “rohan“ would be stored in the Datastore Node 2 (D2)
Thus, our “SET key value” command is done and we can use the same technique for the “GET key” command to fetch the corresponding value for a key from the respective datastore.
Assuming there are M datastore nodes, if we plot the hash(datastore node) for each datastore node on the ring, we would divide our ring into M segments. Considering the uniformly random generated hash values generated by the Hash function, each datastore node is expected to receive an N/M fraction of the load (where N is the number of keys to be stored)
Thus, if a datastore node goes down, only at most N/M keys would be rehashed to the next datastore node found in the clockwise direction on the ring, and the rest of the keys’ location remains constant.
Note: The real location where a key resides is not the bucket in the ring but the immediate next datastore node found in the clockwise direction. The hash value of the key will actually never change on the ring but the key’s location pointer to the immediate next datastore node might get changed if datastore nodes are added/removedas.

Similarly, if a new datastore node is added, only almost N/M keys should be rehashed to the new datastore node, and the rest of the keys’ location remains constant.

Virtual Copies
While the expected load of each datastore node might be N/M, but, the real load might vary depending on how uniformly random the hash function values are.
So, to achieve the real load of N/M per datastore node, the easy way is to make K “virtual copies” of each datastore node implemented by hashing the datastore name (or ID) with K different hash functions to get h1(D0), h2(D0), h3(D0) … hK(D0) and then plot them on the ring.
The ring would look like this:

If we do this for all the datastore nodes, even with an average hash function, we would end up achieving the true load of N/M per datastore node.
You can also consider making more virtual copies for powerful datastore nodes (i.e. nodes with higher CPU, storage, etc.). Hence, they get more <key, value> storage as compared to the less powerful datastore nodes.
Conclusion
Consistent Hashing is a great algorithm for managing the data in a distributed system, especially because there is a constant change in the number of datastore nodes. It’s a great application for load balancing your data, distributed caching, and many more. This algorithm is one of the key reasons we can use applications/websites having more than a billion users with milliseconds latency.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. In the upcoming editions, I will be sharing the code implementation of the Consistent Hashing with you. Stay tuned!
Resources
https://en.wikipedia.org/wiki/Hash_function
https://www.toptal.com/big-data/consistent-hashing
https://web.stanford.edu/class/cs168/l/l1.pdf
https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Very detailed article. Just one question:
> hashing the datastore name (or ID) with K different hash functions to get h1(D0), h2(D0), h3(D0) … hK(D0)
Why should I use many different hash functions for each virtual node? Shouldn't the hash function be always the same for keys, nodes and virtual nodes?
Are you sure the output of a hash function needs to be shorter length than the input?
I don't think that is correct