
What makes Kafka so fast and efficient?

Whenever we talk about Kafka being fast, then we often forget the most important question to ask ourselves: in what context is it fast? Is it able to store data with less write latency or does it have high throughput? What does fast mean here?
Answer: “Kafka is fast” means that it can move a large amount of data in a short span of time. The other way to put it is that Kafka is optimized for a very high throughput.
Before we move further, let’s put some numbers to this statement that “Kafka is fast“.
Example 1: There’s this nice blog that benchmarks 2 Million writes per second only using three cheap nodes for the Kafka cluster.
Example 2: Paypal uses a complex Kafka architecture which consists of multiple Kafka clusters. As per their blog in 2023, they are already supporting 1.3 Trillion messages per day. They claim to have 21 million messages per second during the Black Friday sale.
Example 3: As per Agoda’s blog in 2021, they are able to support 1.5 trillion messages per day using their current Kafka architecture. If you translate that number per second, it would be more than 17 million messages per second (considering the average case).
And there are many more cases all over the internet, the bottom line remains the same companies are using Kafka to support their streaming architecture with millions of messages per second. Please note that these companies spend thousands of dollars to maintain their Kafka architecture. It boils down to what maximum throughput you can get out of Kafka while keeping the cost in control.
Let’s look at some of the points which make Kafka fast:
1. Sequential I/O
There are two kinds of disk access patterns: random disk I/O and sequential disk I/O. Random I/O is an expensive operation because the mechanical arm of the writer has to move around physically on the magnetic disk to perform reads and writes. However, Sequential I/O is straightforward and only appends data to the end, thus providing less latency (the seek time + disk rotational latency) for performing reads and writes.
To put the actual numbers, Sequential I/O can reach up to hundreds of Megabytes per second whereas Random I/O might reach up to hundreds of kilobytes per second.
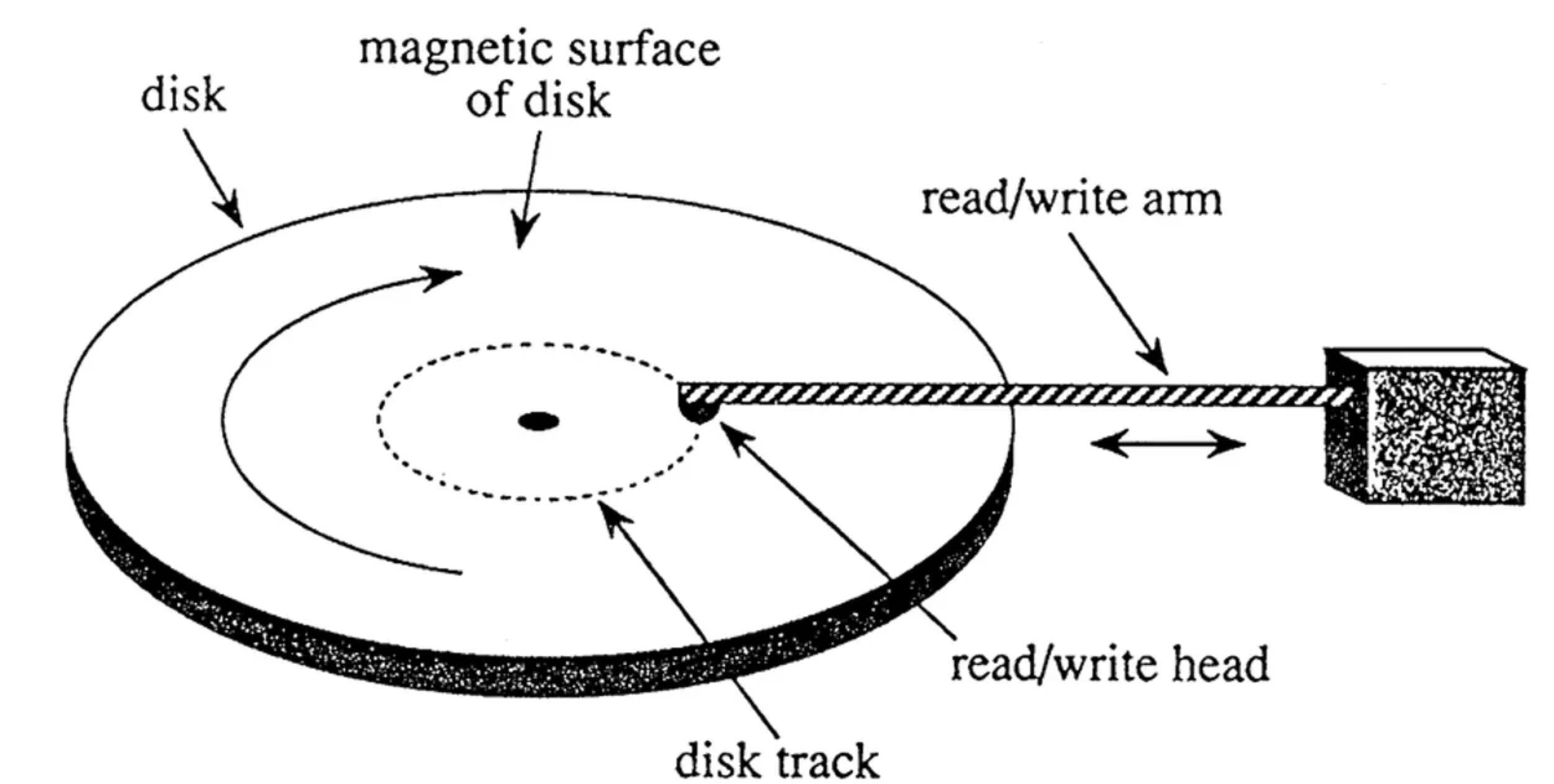
The underlying advantage of using the Sequential I/O is that you just have to wait for the latency penalty only once (when the mechanical arm moves from its current location to the desired location on the disk) and then write data contiguously without any further penalty. However, you have to pay this latency penalty in random I/O for every read/write operation.
Kafka uses the Sequential I/O strategy. Kafka topics are append-only logs, and their contents are immutable. In this way, topics are similar to application log files. Because the events never change once written, Kafka topics are easy to replicate, which allows them to be durably and reliably stored across many nodes in the Kafka cluster.
You might ask that if sequential I/O is so efficient, then why to use random I/O at all? Please note that random I/O is inevitable. As we create, delete, modify, read data in a database, the mechanical arm is bound to move and perform the requested operation (read/write) on the disk and thus your database will eventually perform random I/O operations. That’s why it’s recommended to use indexes as much as possible atleast for reading as they provide a logical sorted dataset and promotes more sequential I/O access pattern than random I/O.
Also, the concept of append-only logs is not something new at all. You must have heard about Write-Ahead logging in PostgreSQL. It works on the same principle where the statement is logged first and the actual data which needs to be modified is persisted later to the disk. Read here for more details about WAL.
2. Zero Copy Principle
To understand the zero-copy principle and how it benefits Kafka, let’s understand both situations: with and without the zero-copy principle and how it impacts data transfer between producers and consumers in Kafka.
Let’s first consider Data transfer without the Zero Copy Principle:
First, the OS (operating system) reads data from the disk and loads it into the OS buffer.
Then, the data gets copied from the OS buffer into Kafka’s application buffer.
Then, the data gets copied from Kafka’s application buffer to the Socket buffer.
Then, the data gets copied from the Socket buffer to the NIC(Network Interface Card) buffer. What is NIC? It’s called a Network Interface card which is a hardware component attached to a chip that’s responsible for sending data packets at the network layer.

As you can see in the above case, the data got copied to Kafka’s application buffer and Socket buffer for no good reason. It could’ve been directly copied to the NIC buffer.
Now let’s consider data transfer with the Zero Copy Principle:
First, the OS (operating system) reads data from the disk and loads it into the OS buffer.
Then, the Kafka application sends a system call called “sendfile()“ to tell the Operating system to copy the data directly from the OS buffer to the NIC buffer.

This is called the “Zero Copy principle”, which makes data transfer between producers and consumers efficient by directly copying the data from the OS buffer to the NIC buffer.
One thing to note here is that “sendfile” is a system call. It does not have anything to do with Kafka as a streaming platform. “SendFile” is a system call that transfers data between file descriptors. It allows the kernel to directly transfer the data between the source(OS) and destination(network socket), reducing memory usage and context switching between user and kernel space.
User space refers to all code that runs outside the operating system's kernel and the kernel space refers to a space reserved exclusively for running the kernel and it’s related operations.
Overall, here are some of the benefits of using this “Zero-Copy” technique:
Reduced CPU usage: If we are doing less data copying, that means less CPU utilization and fewer context switches between the user space and kernel space. This allows the CPU to perform more tasks.
Less Latency: Hypothetically, if it was taking 100ms earlier to copy the data without the zero-copy technique, now it would take only 50ms with zero-copy. Thus, data can be transferred more quickly between producers and consumers.
Another point that could contribute to overall Kafka’s success is that it’s distributed: Kafka stores data in a distributed manner on multiple brokers. Every broker in the Kafka cluster stores a subset of the whole data and can process that independently. As the data increases, you can add more brokers to add more parallelism to your Kafka cluster. Thus, Kafka is easily horizontally scalable and you don’t have to worry about increasing volume of data.
Some more important points contribute to the overall success of Kafka but I’ll save that for some other day.
That’s it, folks for this edition of the newsletter. Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Book exclusive 1:1 with me here.
Resources
Why is Kafka fast by ByteByteGo
Understanding I/O: Random vs Sequential
How do Hard disk drives work?
awesome article!! nicely covered the OS and computer network part