

Text Based Search: ElasticSearch
Text Based Search: ElasticSearch
This article is a beginner-friendly article on how ElasticSearch fits in an architecture and how it works internally.

Introduction
Elasticsearch is a distributed search and analytics engine that stores and indexes data for fast search and analysis. According to Wikipedia, ElasticSearch is based on Apache Lucene. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. It’s part of the Elastic stack which includes Kibana(for data visualization) and LogStash(for data processing). The ELK stack is one of the most popular stacks used for logging & analyzing purposes.
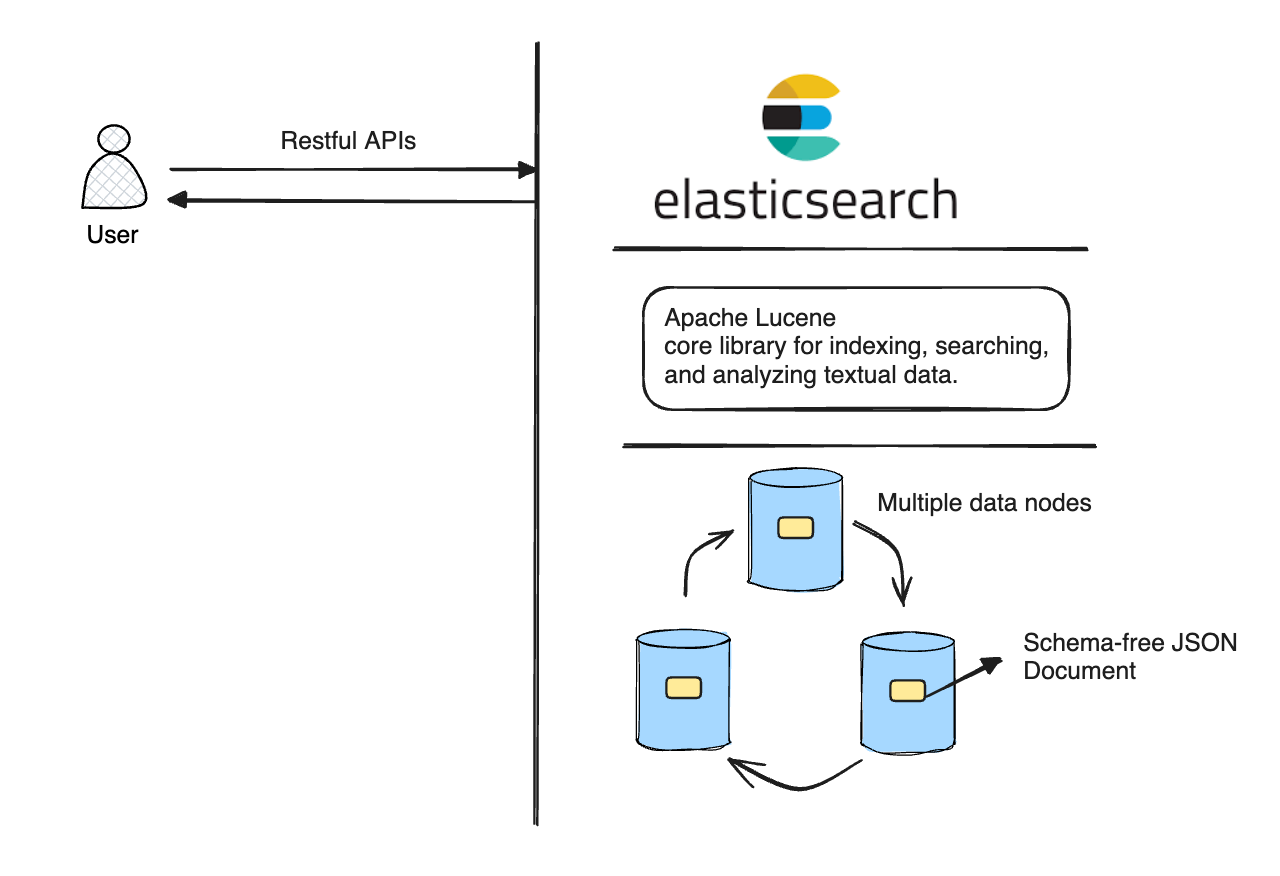
Let’s try to break down some jargon here:
“Search Engine”: A Search Engine is an information retrieval software from one or multiple computer systems. For example: Google.
“Apache Lucene”: Apache Lucene is a high-performance search engine library written entirely in Java.
“distributed, multitenant-capable”: ElasticSearch stores its data across multiple machines and is used to serve multiple services(tenants) in an architecture.
“full-text search engine”: ElasticSearch is designed to efficiently store, index, and retrieve textual data. It enables users to search for individual words, phrases, or even entire sentences.
“schema-free JSON documents”: ElasticSearch allows you to store and index your data as a document in the JSON format without defining a strict schema upfront. This JSON-format data can evolve over time, and you don’t need to change the schema.
A big shout out to the sponsor for this edition who help to run this newsletter for free 🎉 Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams who want to speed up their work flows and consolidate their technical assets.
Documents in ElasticSearch
How does ElasticSearch store data?
As per the official documentation, Elasticsearch serializes and stores data in the form of JSON documents. A document is a set of fields, which are key-value pairs that contain your data. Each document has a unique ID, which you can create or have Elasticsearch auto-generate.
Here’s an example of a document stored in ElasticSearch:
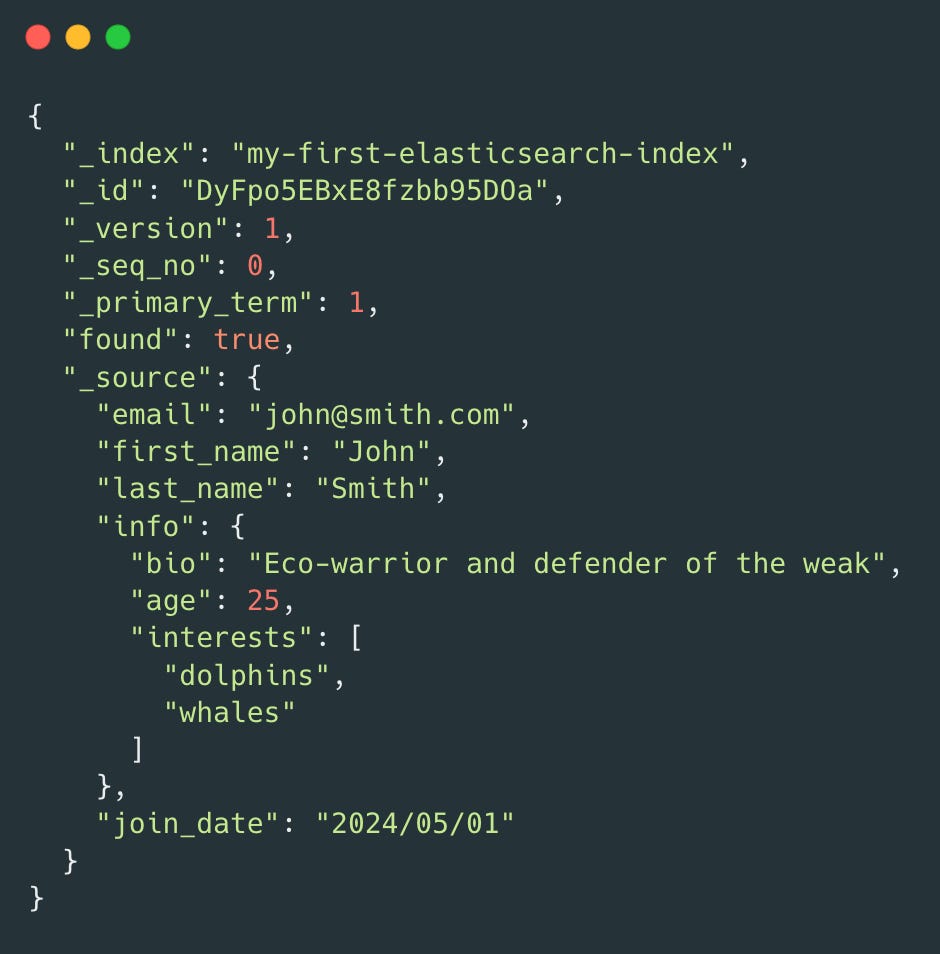
The above is an example of a document which is indexed. An indexed document contains data and metadata. The metadata fields are represented using the underscore symbol. For example: in the above document, the following fields are metadata fields:
_index: The name of the index where the document is stored._id: The document’s ID. IDs must be unique per index.
Inverted Indexing in ElasticSearch
Elasticsearch uses an inverted index, which is a data structure that maps keywords to the documents they appear in. This allows for efficient searching and retrieval of documents based on keywords.
The term inverted index is named so because of the inverted behavior. The typical indexing works in the forward manner where you have an ID and you are trying to fetch the full record. In the Inverted Index, you have the word and you are trying to see in which all documents is this word appearing.
Refer to the below image to understand the difference between Forward index and the Inverted Index. Please note that “I”, “am”, “My” and other similar words could be a noise to your ElasticSearch Inverted index and thus should be filtered while creating an inverted index. These are common text processing techniques like removing stop words(“the”, “is”, “am” etc.), doing stemming of words i.e. reducing them to the base form (“running” to [“run”, “ran”]) and are popularly used across the industry.

Lucene builds inverted index using SkipLists. Read more about SkipList here:

Index, Shard and Segments in ElasticSearch
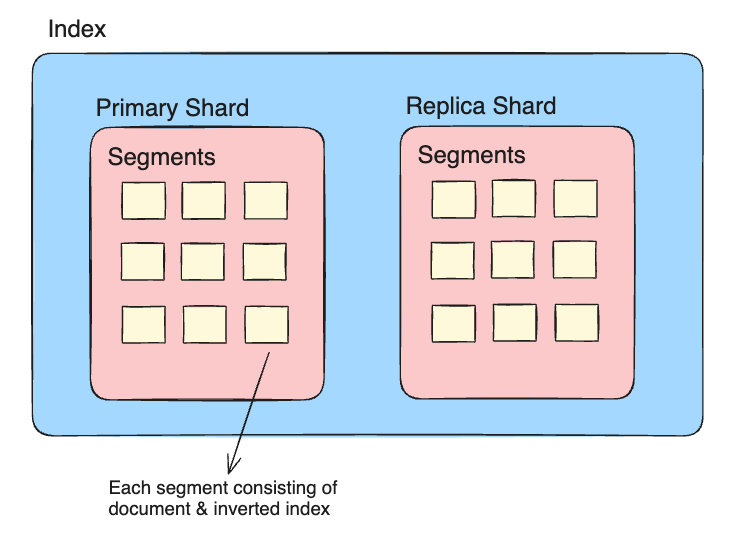
Index
Firstly, don’t confuse index in ElasticSearch with index in a SQL database. Data is stored in the database form and indexed to retrieve faster in SQL. However, in the ElasticSearch, the data is stored as an index and retrieved from the index only. So, index is like a logical namespace to store similar kind of data. There could be multiple indexes in your ElasticSearch cluster. Every index consists of one or more shards.
Shard
Each shard is an instance of a Lucene index, which you can think of as a self-contained search engine that indexes and handles queries for a subset of the data in an Elasticsearch cluster. Thus, out of the whole data contained in a single index, a subset of that data is managed by a single shard.
There can be two kinds of shards present in an index: Primary & Replica. A "primary shard" is the main home for a document. A "replica shard" is a copy of the primary shard that provides (1) failover in case the primary dies and (2) increased read throughput.
Segment
Each shard contains multiple segments, where a segment is an inverted index. A search in a shard will search each segment in turn, then combine their results into the final results for that shard.
Elasticsearch is a real-time search engine that indexes documents in memory and periodically flushes them to disk as segments. These segments are searchable units that store both the document content and an inverted index for efficient term-based searching.
As more and more documents are created, more and more segments are flushed onto the disk and as a result, the search query response time increases.
To optimize search performance, Elasticsearch employs a merging process that combines smaller segments into larger ones. This reduces the number of segments that need to be searched, improving search efficiency. Segments are immutable, meaning they cannot be modified once created. When a document is updated, Elasticsearch indexes a new version and marks the old one as deleted. The merging process removes these deleted documents. This is a very popular technique. Remember SSTables :D ?
Usecases of ElasticSearch
Needless to say, ElasticSearch is one of the most popular search engine widely used across the tech industry. Here are a few usescases:
Full Text Search: This is the most common use case for Elasticsearch. It involves indexing documents and then searching for specific terms or phrases.
Analytics Store: Elasticsearch can also be used as an analytics store. This involves storing data and then querying it to get insights.
Auto Completer: Elasticsearch can be used to provide auto-complete suggestions as users type. This can be observed while typing on any e-commerce website and dropdown appearing full of suggestions.
Spell Checker: Elasticsearch can be used to correct misspelled words.
Alerting engine: Elasticsearch can be used to send alerts based on specific conditions.
General purpose document store: Elasticsearch can be used to store any type of document.
Read to the detailed use cases by the ElasticSearch team over here.
That’s it, folks for this edition of the newsletter. Hope you liked this edition. I wanted to explore more around Semantic Search but will reserve that for the future editions.
Please consider liking 👍 and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
ElasticSearch by Wikipedia
Full Text Search by Wikipedia
Apache Lucene by Wikipedia
Indices, Documents and fields: Official Guide on ElasticSearch
Introduction to ElasticSearch by Justin Jones
Inverted index is built using Skip-Lists: StackOverflow answer
good read can we have a blog on how do we ingest data to ES and the how process of CDC works?