


A deep dive: What is LSM tree?
This article deep dives into what is an LSM tree and how does it work internally.

What is the problem with B-Tree?
The underlying data structure used in PostgreSQL for storing data and fast retrieval is B-tree. B-tree is a self-balancing search tree data structure that stores data in a sorted fashion and does all operations — Search, Insert, and Delete in O(logn) complexity where n is the number of nodes in the tree.
B-trees are optimized for balanced reads and writes. However, as the data grows, the B-trees based data storage engines start becoming a bottleneck because of write amplification.
What is write amplification? Whenever any write happens in a B-tree, it can lead to updating multiple pages of a database which would involve a lot of random disk I/O. This is called write amplification. Thus, the B-Tree limits how fast the data can be ingested into a SQL database.
What can we do better here? Enters the solution: LSM tree
Hint: Append only Logs
What is an LSM tree?
LSM tree stands for Log-Structured Merge tree. It’s a data structure popularly used in databases and file systems. It is optimized for fast writes. The LSM trees are a popular data structure choice for implementation in NoSQL databases. For example: Cassandra, SyllaDB, RocksDB. Let’s dive deep into it to understand better.
An LSM tree consists of two key components: Memtable and SSTables.
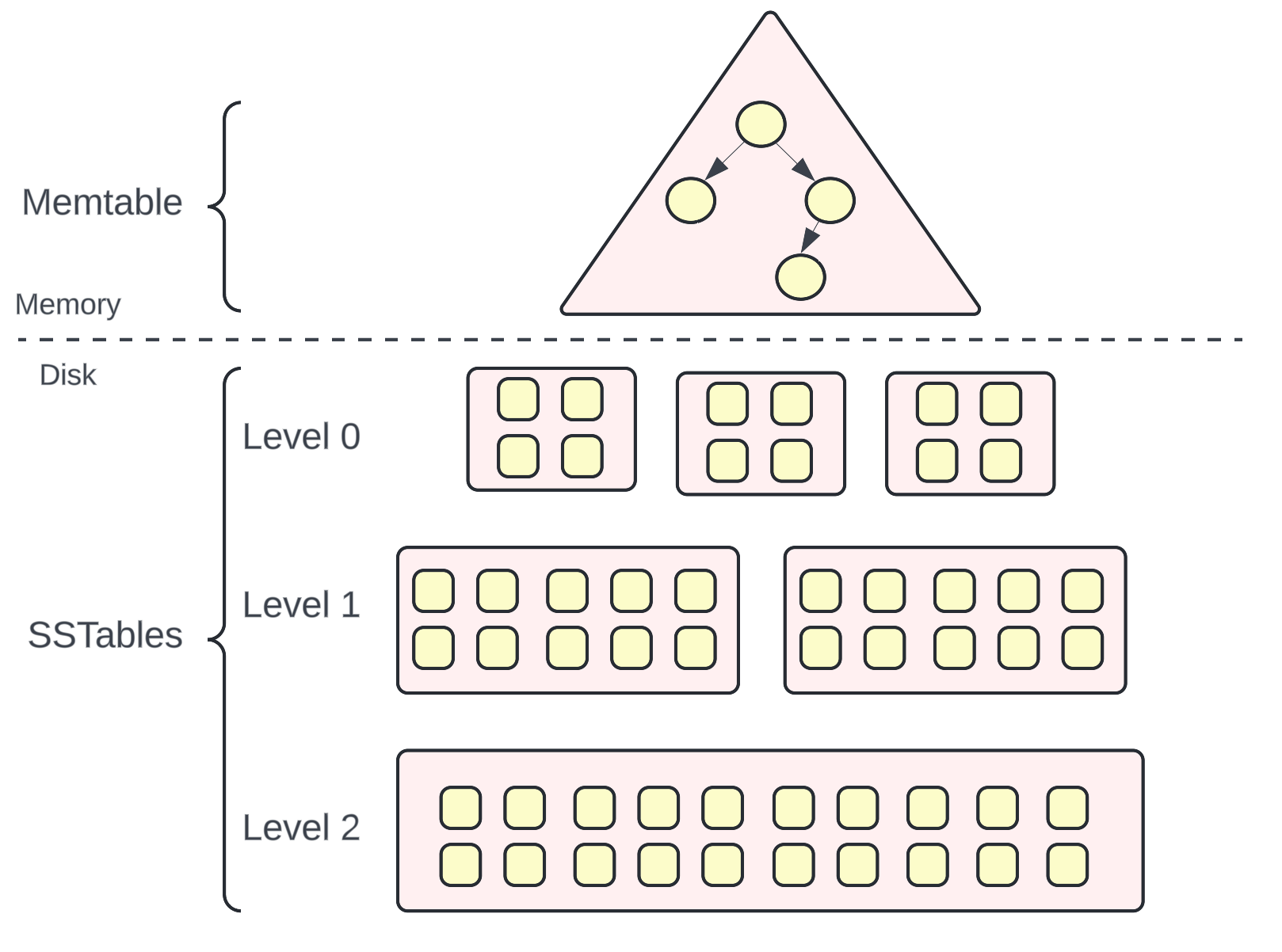
Memtable
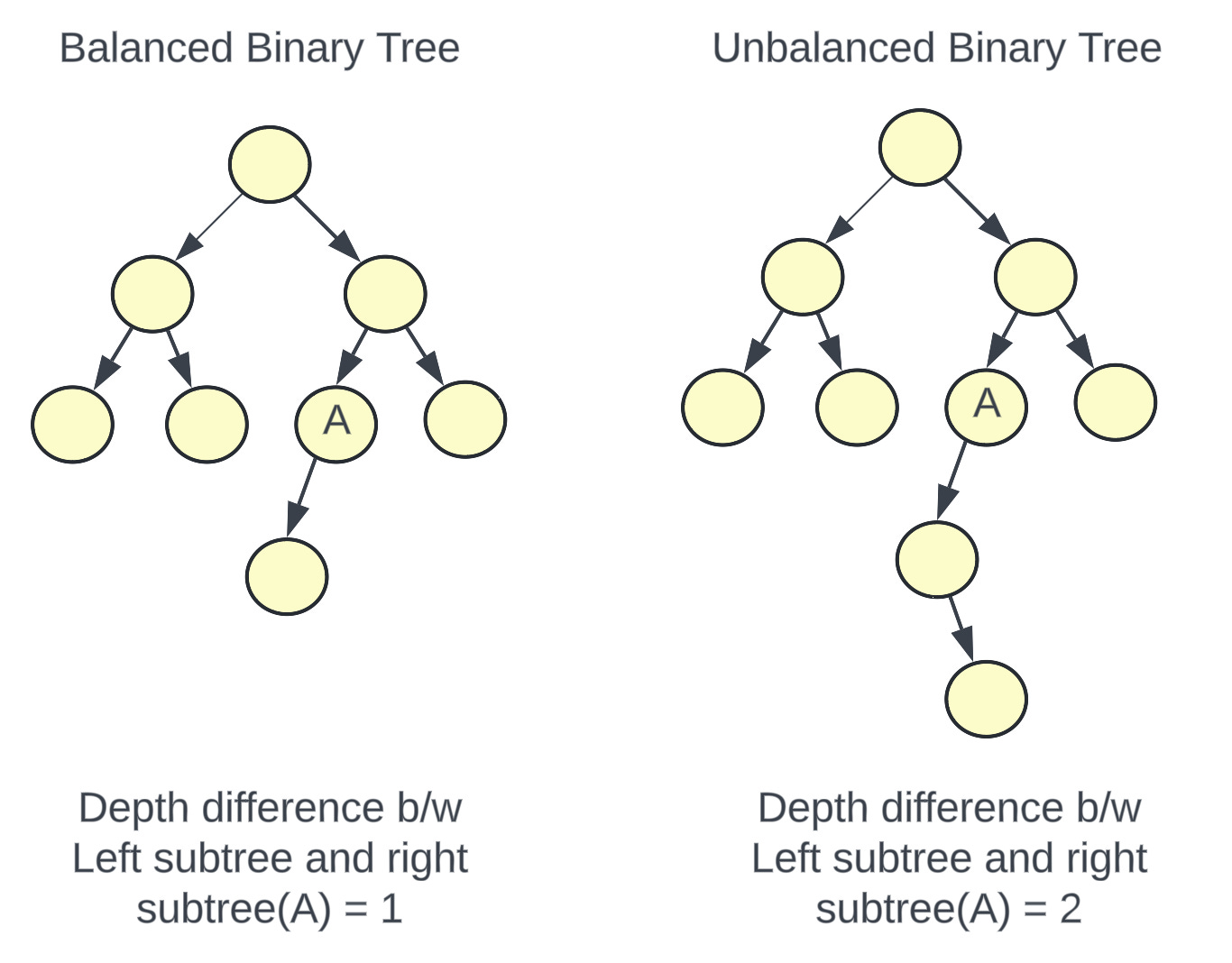
Memtable is a data structure that holds data in memory before it’s flushed into disk. It is usually implemented as a balanced binary search tree.
A balanced binary search tree is a data structure where the difference between the depth of the left subtree and the right subtree is 0 or 1 for every node. Since the tree is balanced, the height of a balanced binary tree is O(logN) where N is the number of nodes in the tree.
SSTables (Sorted String Tables)
SSTables stands for Sorted String tables. They contain a large number of <key, value> pairs sorted by the key. They are permanently persisted on the disk and are immutable i.e. the content in the SSTables cannot be modified.
Compaction of SSTables
As more data comes into the database, more SSTables are created on the disk. The contents of SSTables are immutable to gain the advantage of Sequential I/O. Thus, if there is any update coming for the same key, it is also treated as a new write operation.
However, a large number of operations to the same key could lead to having multiple SSTables. If there are multiple SStables, the disk space usage might shoot up. To keep the disk space usage in check and avoid duplicate entries for the same key, there is a periodic compaction process of merging smaller SSTables into a larger SSTable. Once the merge is complete, the original Level 0 SSTables are deleted and no longer used.
So, you can imagine, that as more data comes into the database, the merge process kicks in when the space utilization reaches the configured threshold for a particular level. New SSTables are created at Level X + 1 and all the old SSTables at Level X are discarded.
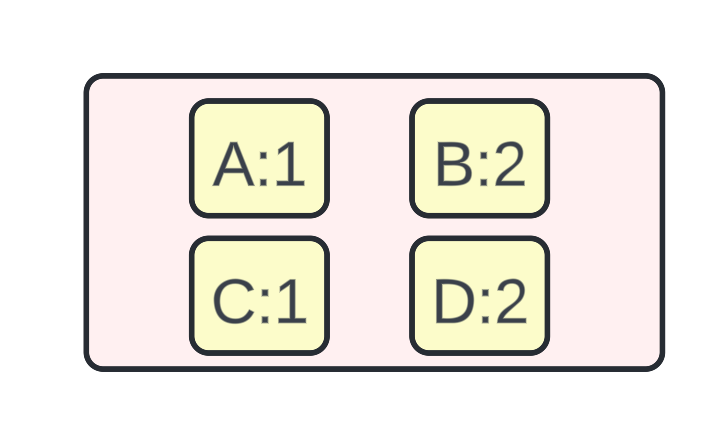
For the following diagram, consider a few points:
Initially, all the <key, value> pairs in the SSTables at Level 0 are sorted by the key.
At Level 0, there are two operations for the Key:A. The first operation is Set(A, 1) and the second operation is Delete(A). When the compaction happens, the key:A is deleted and no longer present at the SSTable at Level 1.
There are two key, value pairs for the Key:C. The first one is C:1 and the second one is C:3. When the compaction happens, the latest key, value is taken into account for the same key and thus C:3 is retained in the new SSTable at Level 1.
You would realize now that merging SSTables is similar to the Merge algorithm of two sorted arrays.
There are different Compaction Strategies used in an LSM tree. For example: Size tiered compaction (optimized for write throughput) v/s Leveled compaction (optimized for read throughput). I’ll save this discussion for some other day.

Now that we’ve understood what are the key components of an LSM tree, let’s understand how Reads and Writes work in the case of a database that uses a Log-Structured Merge Tree.
How does a Write happen using an LSM tree?

When a write request comes to a database that uses an LSM tree, the write request change log is captured in a Write-Ahead Log file for durability. Read more about the Write-Ahead Log here.
Parallelly, the write request changes are stored in an in-memory structure called Memtable. As discussed earlier, memtable is usually implemented as a balanced binary search tree.
When the memtable reaches a certain threshold, the memtable is sorted and all the data is flushed to the disk in the form of SSTables (Sorted String tables).
How does a Read happen using an LSM tree?
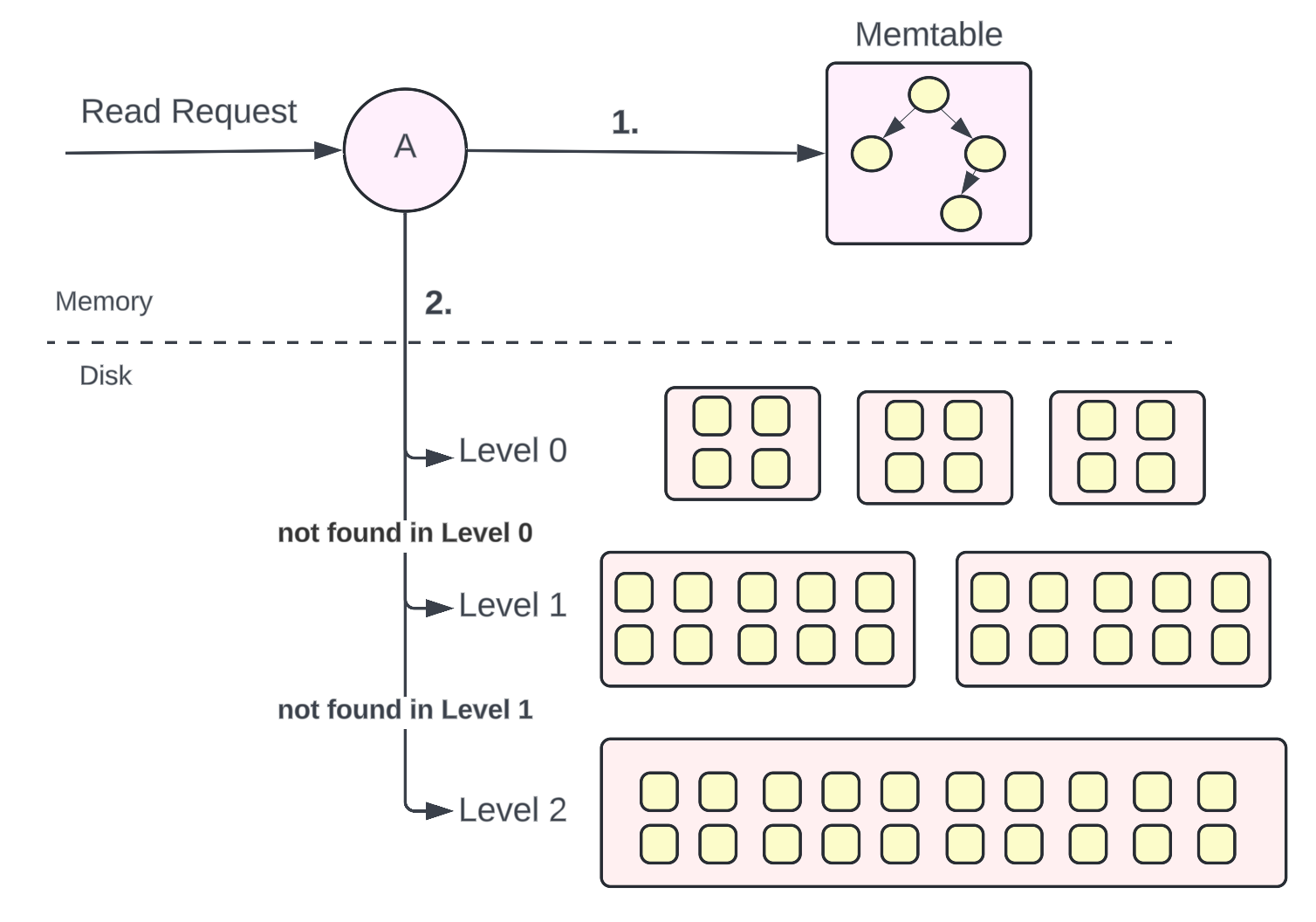
When a read request comes, the key is first searched in the in-memory memtables. If the key is found, the value is returned at lightning-fast speed because of faster access from memory compared to the disk.
If the key is not found in the memtables, it is searched on the disk. Firstly, it is searched on the Level 0 SSTables, then the Level 1 SSTables, then the Level 2 SSTables, and so on.
Optimization on Reads
Since the SSTables are sorted in nature, we can do a logarithmic search to find the desired key. Still, the logarithmic search would be a costly read because we would be doing a lot of disk I/O operations to figure out if a key exists in the SSTables at a particular level or not.
What can we do better to optimize the reads further? Remember Bloom filters?
Bloom filters are a space-efficient probabilistic data structure that helps in solving the problem: “Does the element exist in the set (data structure) or not?”
We can implement a bloom filter data structure per Level of the LSM tree to represent if a particular key exists in the Memtable/SSTables at a particular level or not. We know that there could be some false positives but we would end up scanning the whole Level much faster compared to doing a Logarithmic search on all the SSTables at every level. Memtable is also not an exception here. Checking if the key exists in bloom filters would be much faster on average compared to reading the self-balancing tree of the memtable in memory.

Conclusion
Well, that’s about LSM trees. What’s important to realize here is how LSM trees are so efficient for heavy write throughput due to the append-only nature of the SSTables. This is because of Sequential I/O — the same factor when we discussed about why Kafka is fast.
It’s also important to understand writing to a WAL is also the same approach used in PostgreSQL but the underlying data structure (B-tree used in PostgreSQL) is different from the LSM trees used in Cassandra.
Also, LSM trees find their application in various real-world systems: NoSQL databases, Search Engines, Time-Series databases, etc. I will mention more about this in the future when case studies are discussed.
I hope this discussion is worth it for your future needs. That’s it, folks for this edition of the newsletter.
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
The Secret Sauce Behind NoSQL: LSM Tree by
An Intro to LSM Trees (Shoutout to )
Memtable and SSTable by Mauricio Poppe
Cassandra Documentation on Memtable and SSTables
Understanding the Log structured Merge Tree by Mandeep Singh
Thanks for the great article 👍
For The section:
However, B+trees have a linked list of leaf nodes. Thus, you can just use one path to traverse down the whole tree and then access all the keys using links at the leaf nodes. Thus, making sequential access more efficient in case of B+Trees.
My question is:
How is the B+ tree read sequential on disc (assuming HDD)?
From your example, I believe the leaf nodes 1,3,4,5,6,10,12... are not stored in sequential pages on disc. The reason is because otherwise, as soon as you add a new node , say 7, you will have to move all pages after that (10,12...) which will become an extremely expensive operation.
When I read "sequential", I believe the context should be sequential disc read (in context of a hard disc, for SSDs, it doesn't matter).
So, even though each leaf node is pointing to the next leaf node, it will be a random disc access.
Really good read!!