
B-Tree vs B+ Tree: Key Differences Explained
This article deep dives into how data storage happens in a B-Tree and B+Tree.

Brief Overview of Tees
A tree data structure is a hierarchical data structure that consists of nodes connected by edges. It's a non-linear data structure, meaning the elements are not stored sequentially like in arrays or linked lists. Instead, they are organized in a tree-like structure. It consists of key components like Node, Edge, Parent-Child relationship between the nodes, Root, and Subtree, etc.
To understand more about B-Trees and B+Trees, let’s understand more about basic kinds of trees and then about Self-Balancing Binary Search Tree.
Binary Tree: A tree where each node has at most two children.
Binary Search Tree (BST): A binary tree where the left child value of a node is always less than the parent node value, and the right child value is always greater than the parent node value.
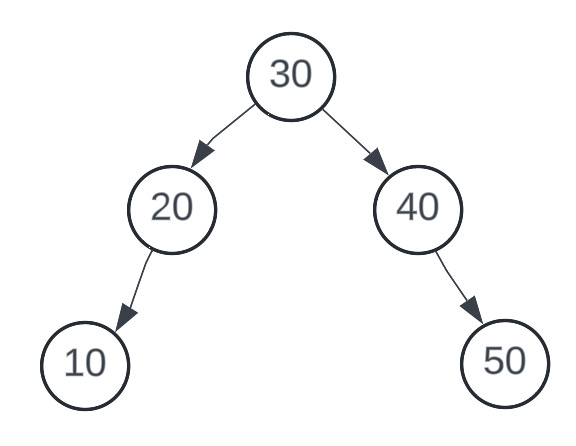
Balanced Binary Search Tree: This is a binary tree where the difference in height between the left and right subtrees of each node is at most 1.

At this point, you can imagine why we need Balanced Binary Search Trees: so that the trees don’t grow in a skewed fashion and future operations: insert, search or delete can be performed quickly.
Self-Balancing Binary Search Tree: A self-balancing BST automatically adjusts its shape and height whenever a node is inserted or deleted to maintain balance. A self-balancing BST keeps its height to a minimum, which ensures that its operations maintain a worst-case time complexity of O(log_2n).
B-Trees and B+Trees are NOT self-balancing Binary Search Trees(BST) because they don’t contain only two children nodes, but only self-balancing search trees that are built on the same technical nuances of a BST.
What is a B-tree?
As per Wikipedia, B-tree is a self-balancing tree that maintains sorted data and allows searches, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree allowing nodes in a tree to have more than two children. Thus, B-Tree are called m-way trees with some set of rules where "m" represents the maximum number of children a node can have.
Probably, not important, but here are the specific rules that define a B-tree of order m:
Number of keys: Each node must contain at least m/2 - 1 and at most m - 1 keys.
Number of children: Each node must have at least m/2 and at most m children.
Leaf nodes: All leaf nodes must be at the same level.
Root node: The root node can have fewer than m/2 children, but it must have at least 2.
These rules ensure that B-trees remain balanced and efficient for search, insertion, and deletion operations. The value of "m" is typically chosen based on the specific application and the characteristics of the underlying storage system.
Take a pause here and literally imagine that B-Tree is a self-balancing tree. Any insert, update, delete operations would all lead to rebalancing of the B-tree in such a way that it maintains it’s height upto O(log_mN) so that future operations also remain optimized. Here, m = order of the B-Tree and N = number of nodes in the B-Tree.
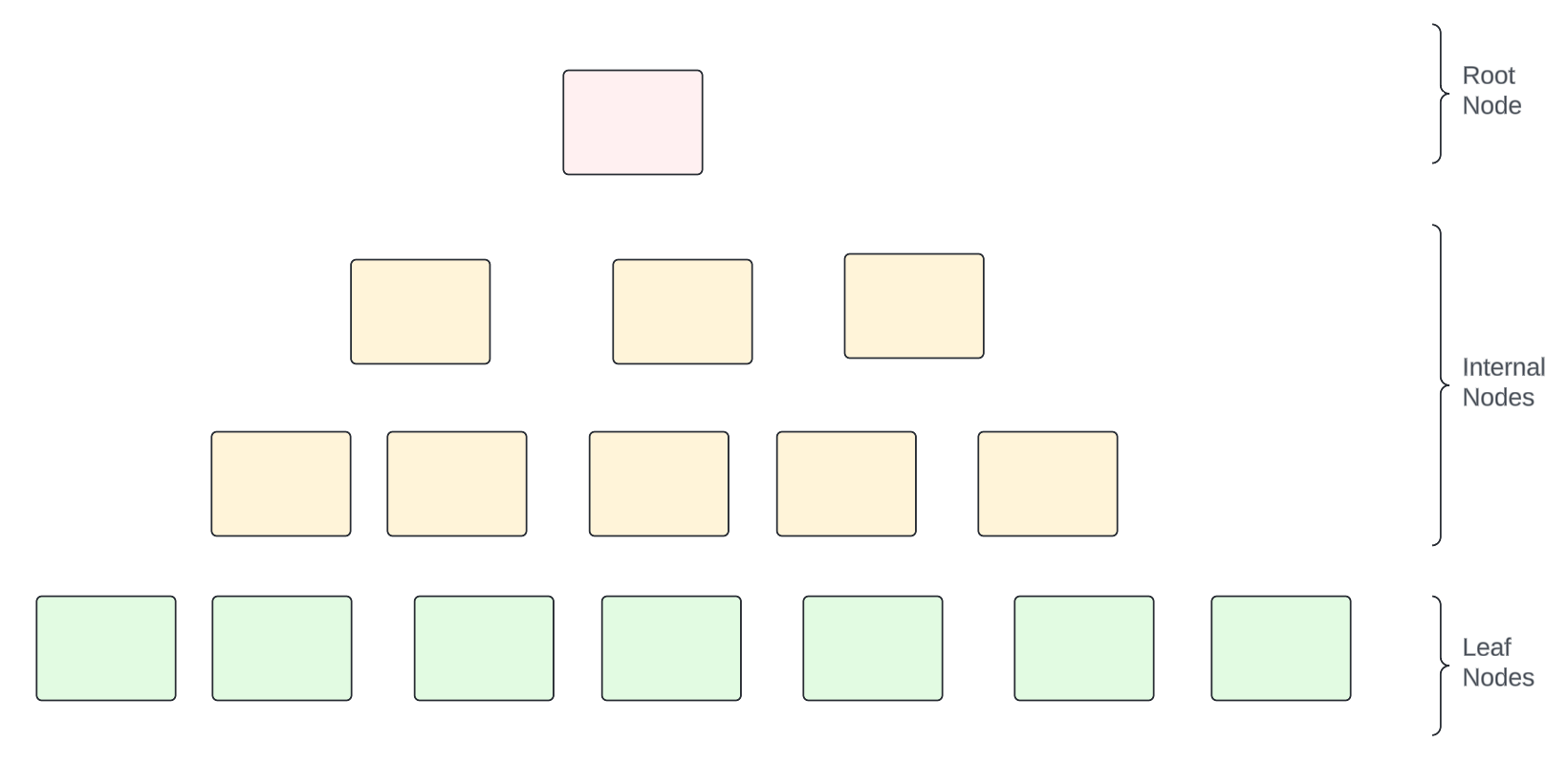
Different types of nodes in a B-Tree
There are three kinds of nodes often discussed when talking about a B-Tree: Internal nodes, leaf nodes, and root nodes.
Unlike traditional Binary search trees where you can only store one key in a single node, the B-Tree allows you to store multiple keys in a single node which eventually allows the tree to have a larger branching factor and thus a shallower height.
Let’s see how data storage happens inside a B-Tree.
Data storage inside a B-Tree
Whenever we talk about storing data in any tree, we are talking about storing keys and potential values within nodes of a tree. The keys are present within all nodes(root, internal, and leaf) but where are values stored makes all the difference.
B-Trees allow you to store keys and values inside the root node, internal nodes as well as leaf nodes. By values, I mean the actual data records of a table. Refer to the below example for visual representation of a B-Tree. It contains two kinds of pointers: child pointers & data pointers.
“Child pointers”: The left pointer of a key points to a node that contains all the keys smaller than the parent node key and the right pointer points to a node that contains all the keys greater than the parent node key. In the below diagram, you can see that left pointer of node containing 15 as key points to the child node starting from 12. The right pointer of 15 (also the left pointer of 20) points to a node that contains keys between 15 and 20. Similarly, the right pointer of 20 points to a node containing key: 25.
“Data pointers”: These pointers actually point to the data record present in the table. Thus, when searching for a key in a B-Tree, the key is found within a node, the data record is accessed quickly and there is no need to traverse the whole B-Tree.


Please observe carefully how I have used the unique ID of the “developers“ table to be used as a key inside B-Tree. These keys are maintained in a sorted fashion inside B-Tree. Thus, searching for a record using this B-Tree is so fast: we just have to find where the developer’s ID exists in the B-Tree using the BST search algorithm and we would get the whole record.
Search inside a B-Tree
Searching inside a B-Tree is similar to how it happens inside a Binary Search Tree. Firstly, begin the search at the root node of the B-tree. Compare the search key with the multiple keys stored in the current node.
If the search key is found in the current node, the associated data record is returned. If the search key is less than the smallest key in the current node, proceed to the leftmost child node. If the search key is greater than the largest key in the current node, proceed to the rightmost child node. Otherwise, find the child node whose keys are greater than the search key but less than the next key in the current node. Recursively search for all the child nodes until the search key is found or the end of the tree is reached.
What is a B+Tree?
B+Tree is an extension of B-Tree with some modifications. B+Tree is also a self-balancing tree that maintains sorted data and allows searches, insertions, and deletions in logarithmic time.
Different types of nodes in a B+Tree
Same as B-Tree, there are three kinds of nodes in a B+Tree: root node, internal nodes and leaf nodes.
Data storage inside a B+Tree
B+Trees allow you to store keys inside the internal nodes but the data records are only stored at the leaf nodes. Similar to B-Trees, there are two kinds of pointers in a B+Tree along with a slight difference:
“Child pointers”: Similar to B-Tree, these pointers point to the child nodes containing the keys in appropriate range.
“Data pointers”: Unlike B-Trees, the data pointers only exist at the leaf nodes and point to the actual data record of the table. Also, the last pointer in a leaf node points to the next leaf node in the B+ tree which resembles a linked list data structure. This pointer helps speed up sequential access.

Search inside a B+Tree
Search starts at the root and proceeds down the tree, comparing the search key with the keys in each node. If the search key is found in an internal node, the search still continues down the appropriate child node and when the search key is found in a leaf node, the associated data record is returned.
Differences between B-Tree and B+Trees
Now, let’s have a macroscopic view of both B-Trees and B+Trees and understand the key differences and how it impacts their performance:
Data Storage: B-trees store data records in internal nodes, while B+trees store them exclusively in leaf nodes. Thus, B+Trees can store more number of keys in the same space compared to B-Trees which holds keys and data pointers as well.
Random/Sequential Data Access: If you want to have sequential access of all the keys in B-Trees, you would have to do a full traversal of the tree i.e. visit possibly each and every node to access all the keys. However, B+trees have a linked list of leaf nodes. Thus, you can just use one path to traverse down the whole tree and then access all the keys using links at the leaf nodes. Thus, making sequential access more efficient in case of B+Trees. For random access, B-trees and B+trees have similar performance. B+Trees search the key quickly, but might do a little delay in returning the data record. On the other hand, B-Trees might take time to search the key, but if found, will return the data record quickly.
If you’re interested in reading more about how B-Trees and B+Trees are used in databases, you should definitely checkout this article: MySQL vs PostgreSQL: Indexing
That’s it, folks for this edition of the newsletter.
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Difference between B-Trees and B+Trees: A StackOverFlow answer
B-Tree Indexing Basics Explained
B-Tree and B+Tree by Wikipedia
B Trees and B+ Trees. How they are useful in Databases by Abdul Bari
Understanding B-Trees: The Data Structure Behind Modern Databases
What a fantastic article Vivek 👏
Just to add, we can also include that B+ tree has doubly linked list instead of singly linked list so that we can traverse in both direction of nodes from the matching node.
Clean and concise. Thanks.