
Sequential vs Random Disk I/O with Code example
This article deep dives into the difference between Sequential and Random disk I/O with some live coding

How do Hard drives work?
Our computers have a permanent data storage called the hard disk (often called the disk). The disk is made of aluminum with a thin magnetic layer at the surface with small magnetic regions(like blocks) whose directions can be manipulated via external magnetic fields. Additionally, there is a read/write arm that has a read/write head at the end of the arm. The read/write head is responsible for reading/writing the data to the disk.
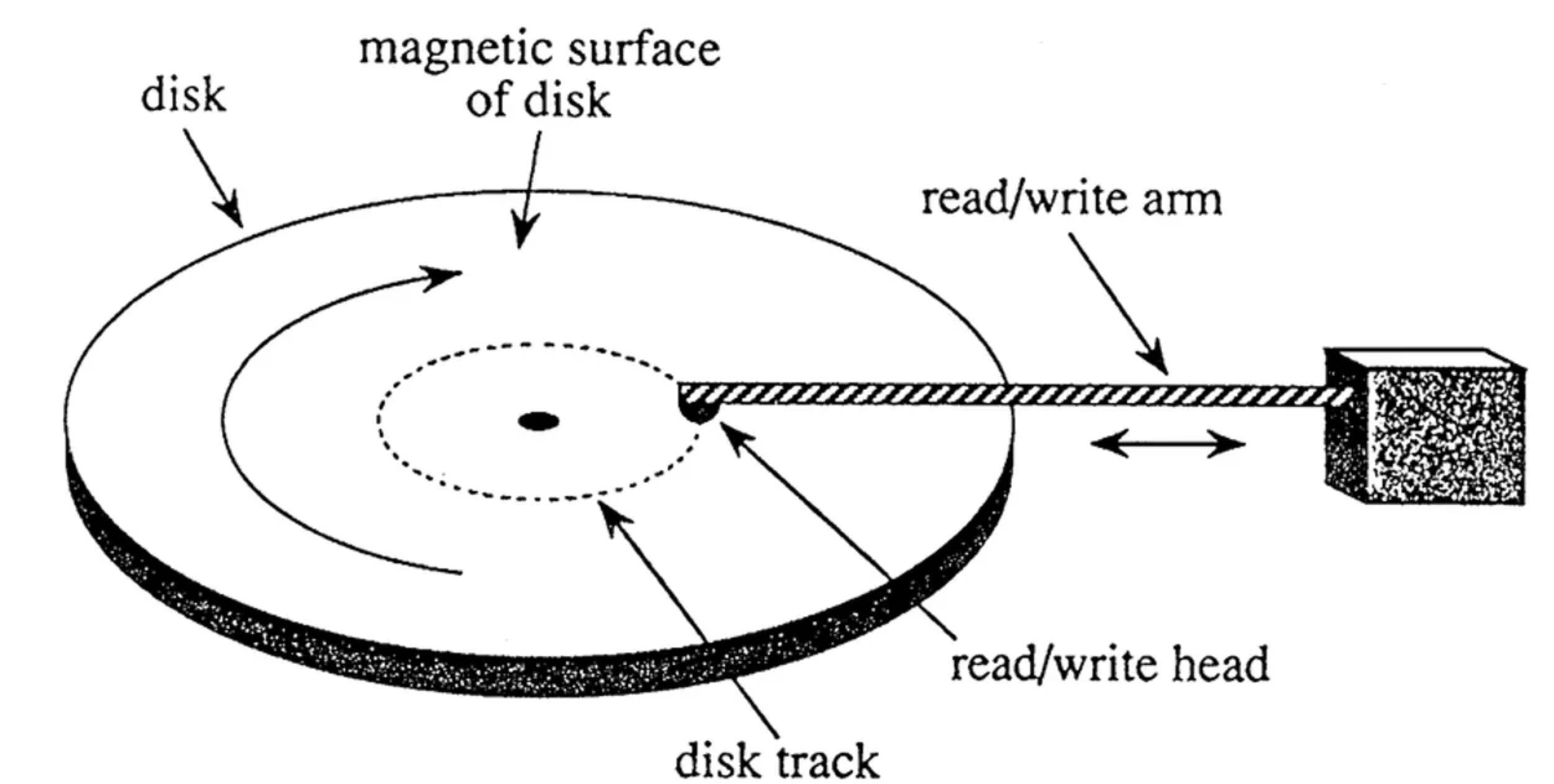
The disk is made up of a series of concentric tracks, and each track is further divided into sectors. A sector is the minimum amount of data you can read or write from/to the disk. The disk usually consists of 512 bytes sized sector but the modern sized HDDs consist of 4096 bytes(4 KB). This means you cannot write information less than 4KB size at a time to the disk. These sectors are magnetically coded to store data. The read/write head is a small electromagnetic coil that is positioned over the surface of the disk.
At this point, it’s also important to highlight that disk sectors are different from blocks/pages in the database. While the sector represents the smallest addressable unit of data that can be read or written to the disk, a block in a database is a logical unit of data that is used to store and retrieve data. A block can consist of multiple sectors. By grouping multiple sectors into a single block, the Operating system can transfer a large amount of data in a single I/O operation and reduce the overhead associated with a single sector access.

How do the read/write operations work on the disk?
Writing Data: When the read/write head writes data, it generates a magnetic field that polarizes the tiny magnetic particles on the disk surface. These particles are aligned in a specific direction to represent a "1" or a "0" in binary code.

Reading Data: When the read/write head reads data, it detects the magnetic polarity of the particles on the disk and interprets it as a "1" or a "0".
Latency Expenditure
As explained in Figure 2, there are tracks and sectors on the disk. Imagine that your read-write head is at point A(refer to the image below) and wants to write some data at point B.
There are two kinds of latency expenditures the read/write arm has to afford for performing any read/write operation to this disk:
Seek Latency: This is the time it takes for the read/write head to move to the desired track on the disk.
Rotational Latency: This is the time it takes for the desired sector to rotate under the read/write head.
For the read/write arm to move from point A to point B, first, it will have to move along the track and then move to the desired sector.

Now comes the million-dollar question: Let’s say you want to perform a set of write operations to the disk: what do you think is costlier: Random I/O or Sequential I/O?
Let’s deep dive and understand better.
Sequential I/O
This is a kind of data access pattern where the data is read or written in a continuous, linear fashion. This means that the next piece of data to be read or written is located adjacent to the previously accessed data. Think of it like reading a book from beginning to end.
In Sequential I/O, if you have to perform a set of write operations on a disk, you would have to afford the penalty i.e. seek latency and rotational latency only once because your read/write arm knows that it has to write all operations continuously next to each other.
Random I/O
In this data access pattern, the data is read/written in a non-sequential order. This means that the next piece of data to be read or written can be located anywhere on the storage device. Imagine flipping through a book to find a specific page and then flipping again through multiple pages to find another page.
In Random I/O, if you have to perform a set of write operations on a disk, you would have to afford the penalty i.e. seek latency and rotational latency every time after an operation because your read/write arm would always change its location after performing one operation successfully on the disk.

At this point, you would be able to guess that there is a huge disk penalty involved in Random I/O compared to Sequential I/O operations. That’s the truth, my friend. Normally, we should try to identify the data access patterns in our application and customize it in such a way that it promotes more Sequential I/O operations as compared to Random I/O. Let’s do some coding to compare the speeds between the two.
Code Example
When you consider running the below code, you will be able to see how Sequential I/O is faster than Random I/O in orders of magnitude for a million write operations.
A few points about the code:
This code writes a million numbers to a file using sequential I/O (writing to the end of the file). Similarly, it writes a million numbers to a file using random I/O (seeks to a random offset before writing).
Measures the time taken for each operation and prints the comparison.
This code has used
FileWriterfor sequential I/O andRandomAccessFilefor random I/O.The random offset is generated using
Math.random()and multiplied by the number of writes to ensure it's within the file bounds. The last multiplier 10 is used for introducing more randomness in the file offset generated to get a more realistic output.

The above code generates the following output:

Conclusion
In our sample code example, the sequential I/O turned out to be approx 20x faster than the random I/O. This proves that writing/reading operations sequentially boosts the performance that we can get out of the disk.
While choosing random I/O or sequential I/O might not be in our full control, we should always analyze our code and try to promote as much as sequential I/O possible or at least try to minimize the number of I/O operations involved on the disk by grouping multiple operations together, processing them in a single pass to reduce I/O overhead.
A good thing to note at this point is the logging systems (like Apache Kafka for distributed logging) have been built using Sequential I/O (append-only mechanism and no modifications allowed in between) thus allowing more throughput. Read more here: What makes Kafka so fast?
That’s it, folks for this edition of the newsletter.
Please consider liking and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Resources
Understanding I/O: Random vs Sequential by flashdba
What is a Hard disk drive by GeeksForGeeks?
How do Hard Disk Drives work?
Random vs Sequential Reading
Hi vivek “This means you cannot write information less than 4KB size at a time to the disk.“
Can you elaborate this more? What if the data is less than 4KB , and thats the last operation that would happen before the server gets shut down how does OS handles this?
Thanks for the article Vivek, great read.
But I don't think this replicates the exact scenario of an HDD write, as OS can still buffer the and reorder writes to optimize for physical disk performance. Also there are abstraction layers like JVM, OS etc. in between which would affect programs ability to simulate same scenario.
C language might closer in replicating this scenario exactly.
Also it'd be great if you can also shed some light on SSD side of things as that'd be an interesting read too.