

SkipList: A probabilistic data structure
SkipList: A probabilistic data structure
This article deep dives into yet another probabilistic data structure called SkipList and how it works.

What is a SkipList?
A SkipList is a probabilistic data structure that supports efficient searching, insertion, and deletion operations on a sorted sequence of elements. It is an alternative to balanced trees like AVL trees or red-black trees(self-balancing BST) but with simpler implementation and often better performance in practice due to its probabilistic nature.
A big shout out to the sponsor for this edition who help to run this newsletter for free 🎉
Multiplayer auto-documents your system, from the high-level logical architecture down to the individual components, APIs, dependencies, and environments. Perfect for teams who want to speed up their work flows and consolidate their technical assets.
Data Storage
A SkipList is essentially a linked list with additional levels (as highlighted in the image). Each level is a LinkedList prepared by skipping over a few elements in the original sorted LinkedList at the lowest level.
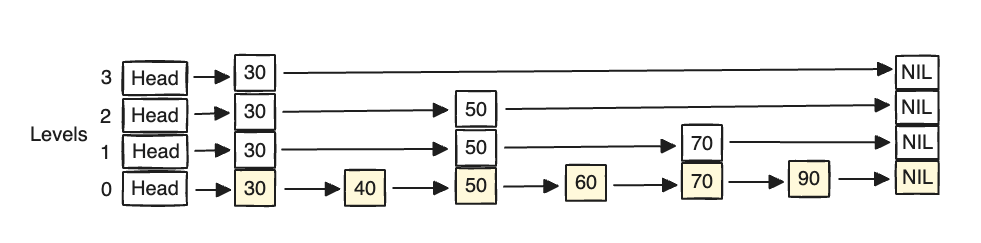
As you can infer from the data structure representation, the last level: Level 0 represents the original list of elements. Level 1 is a LinkedList consisting of the elements above Level 0 by skipping a few elements. Similarly, Level 2 is a LinkedList consisting of skipping a few elements of the LinkedList at Level 1. So on, the list could keep going higher up the Levels.
How does insertion work in SkipList?
Pasting a cool GIF sourced from Wikipedia on the insertion process. Consider reading the steps below the GIF to understand in detail.
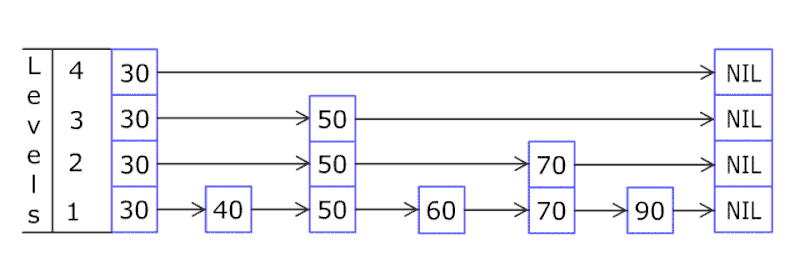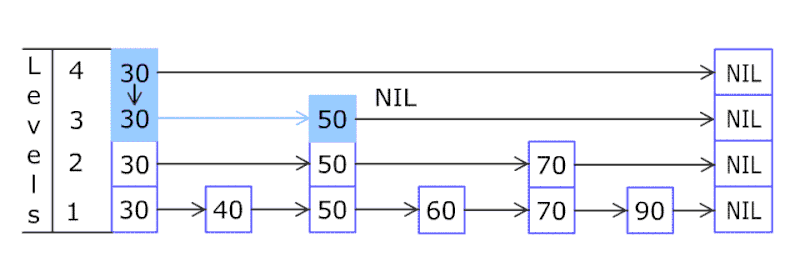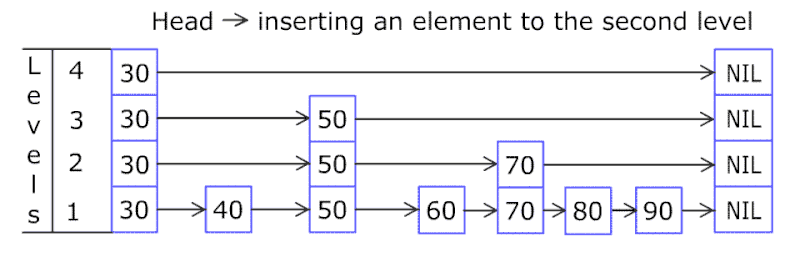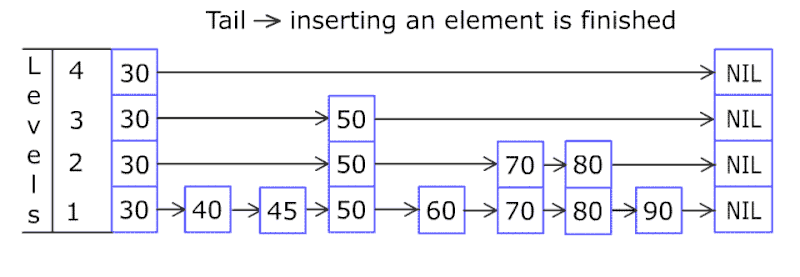
It all starts with a new element insert operation: 80
First, the SkipList checks at the top level: Level 3, and sees if the first element of the LinkedList at the top level is less than the insert element value. i.e. is 80 <= 30?
Since the result (80 <= 30) = false, then we check at the next lower level LinkedList: Level 2, and move forward by one position and compare if 80 <= 50.
The result (80 <= 50) is false, we move on to the next lower level: Level 1, and move forward by one position to find that 80 <= 70 is still false.
Then, finally at the lowest level: Level 0, the comparison 80 <= 90 condition holds true and that’s where we decide to insert the new element.
Then, we flip a coin(doing a probabilistic activity) to see if the new element 80 should be added to the higher levels or not.
If the coin flip results to a Head, we insert it into higher levels of LinkedList and keep on continuing the process unless we get a Tail and terminate the process.
Observations
You would have noticed how we skipped elements 40 and 60 because of LinkedLists that we had at different levels. The more the number of elements present, the better we will be skipping a large subsequence of elements while inserting a new element.
Also, we used a coin to determine if the element should be inserted at a particular level of LinkedList (& other higher levels) to introduce probability into this data structure. It could very well be implemented some other way but I hope you got the idea.
Similarly, Steps 2 to Steps 5 are followed for the update and delete operations in a SkipList. The key thing to note here is: how the SkipLists help in skipping a subsequence of elements for all kinds of operations.
Time Complexity
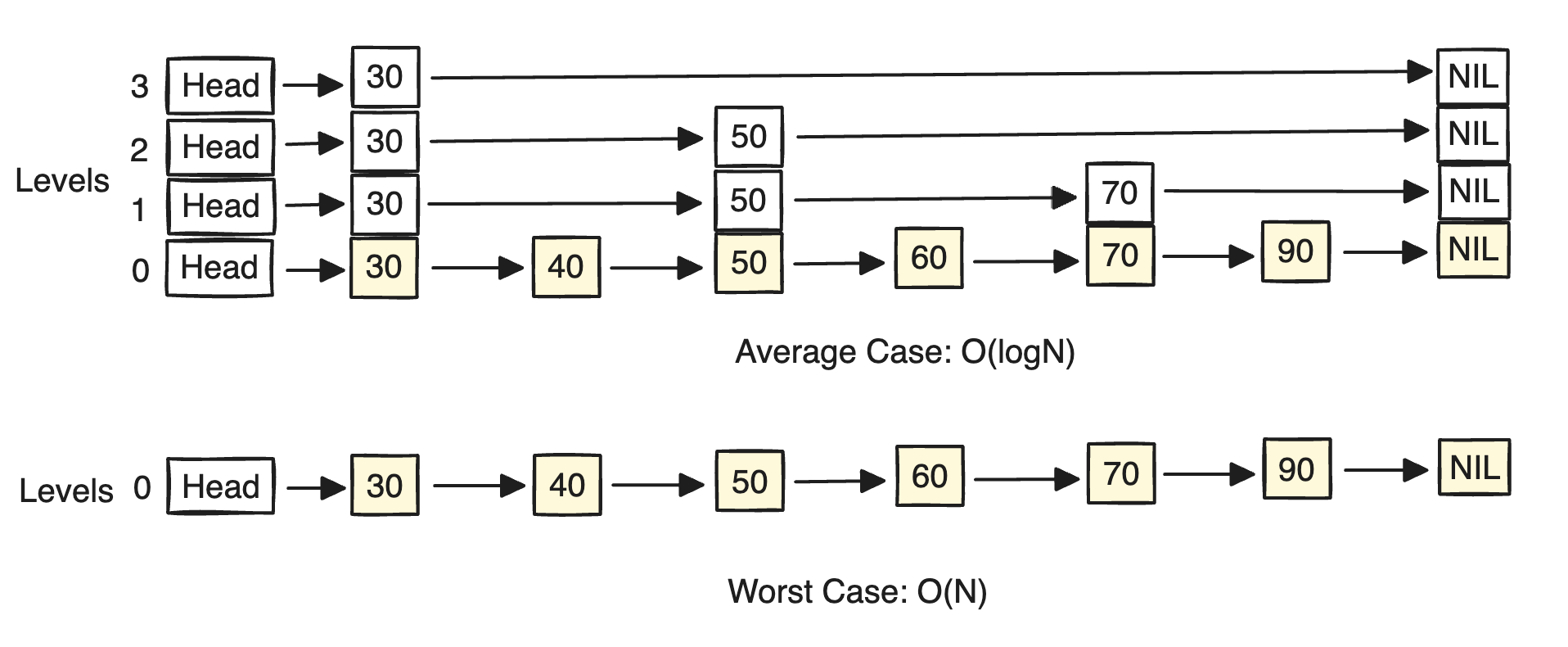
For a LinkedList that consists of N elements, the SkipLists provide average time complexity O(logN) for insert, update, and delete operations whereas the worst-case time complexity is O(N) for the same set of operations.
The key thing to note here is that when a new node is inserted or an existing node is updated or deleted, the algorithm determines the level of the node based on a series of coin flips. The probability of a node being on a higher level is lower than the probability of it being on a lower level. This means that on average, the algorithm will only need to traverse a few levels to find the correct node, resulting in an average case time complexity of O(log n).
But, that being said, it may very well be possible(with very low probability) that coin flips result in an unbalanced SkipList data structure and almost all of the nodes are encapsulated within 1 or 2 levels of the SkipList. That’s why, the worst-case time complexity could still lead to O(N).
Comparison with Self-Balancing BST
A few points regarding comparison with Self-Balancing BSTs like Red-Black Trees or AVL Trees:
A SkipList does not provide worst-case performance guarantees as similar to a BST because of its probabilistic nature used for building it. That’s why, the worst case for SkipList is O(N) while for Self-Balancing BST is O(logN).
Randomized balancing schemes used in SkipList are easier to implement and understand than deterministic balancing schemes used in balanced binary search trees. You might remember that after every insertion, a self-balancing BST needs to rotate/restructure so that future operations remain optimized. This overhead is much less in SkipList.
SkipList needs less space compared to Self-balancing BST. The SkipList has less pointer overhead (Level and the next pointer) compared to a self-balancing BST where each node has two pointers (left and right). The probabilistic nature of SkipList heights means that the average number of pointers per node is generally lower.
SortedSets by Redis
Redis uses SkipLists as the underlying data structure for Sorted Sets. In Redis, Sorted Sets are a collection of members that are ordered by a score. Each member is associated with a score, and the members are stored in ascending order of their scores. For example:
# Create a leaderboard
ZADD top_scorers 100 player1 80 player2 75 player3
# Get the top 3 players
ZREVRANGE top_scorers 0 2 WITHSCORES
# Update a player's score
ZINCRBY top_scorers 10 player1
# Find players with scores between 80 and 100
ZRANGEBYSCORE top_scorers 80 100 WITHSCORESThus, as you can guess, building a real-time leaderboard using Redis’s SortedSets which under the hood uses SkipList is such a powerful use case of the probabilistic data structure that optimizes space as well as the performance(time) of operations.
Other UseCases
Sourced from Wikipedia, here’s a list of popular applications that use SkipList under the hood:
Apache Portable Runtime implements skip lists.
MemSQL uses lock-free skip lists as its prime indexing structure for its database technology.
Cyrus IMAP server offers a "SkipList" backend DB implementation
Lucene uses skip lists to search delta-encoded posting lists in logarithmic time.
Redis, an ANSI-C open-source persistent key/value store for Posix systems, uses skip lists to implement ordered sets.
Discord uses skip lists to store and update the list of members on a server.
RocksDB uses skip lists for its default Memtable implementation.
Before you go…
I hope you visualize the importance of probabilistic data structures in real-world systems present around the world. The problem is the same: Is there a probabilistic way that can improve the time required to perform a certain operation? The underlying fact with all probabilistic data structures is that they reject a large amount of data to be processed in less time with a certain probability and that is what makes it a popular choice in designing systems.
If you’ve not read it already, here are some articles that we covered earlier about probabilistic data structures:
That’s it, folks for this edition of the newsletter. Hope you liked this short edition.
Please consider liking 👍 and sharing with your friends as it motivates me to bring you good content for free. If you think I am doing a decent job, share this article in a nice summary with your network. Connect with me on Linkedin or Twitter for more technical posts in the future!
Thank you for the interesting article!
> SkipList needs less space compared to Self-balancing BST. The SkipList has less pointer overhead (Level and the next pointer) compared to a self-balancing BST where each node has two pointers (left and right)
1. So each node in both data structures have same number of pointers right? How does that make skip-list more memory efficient?
2. Aren't we also storing few elements multiple times? Shouldn't that make skip-list consume more memory?
3. For lists at higher level, how do we insert in the middle of the linked list if we don't store next and previous pointer (along with height to move down).